Dataset
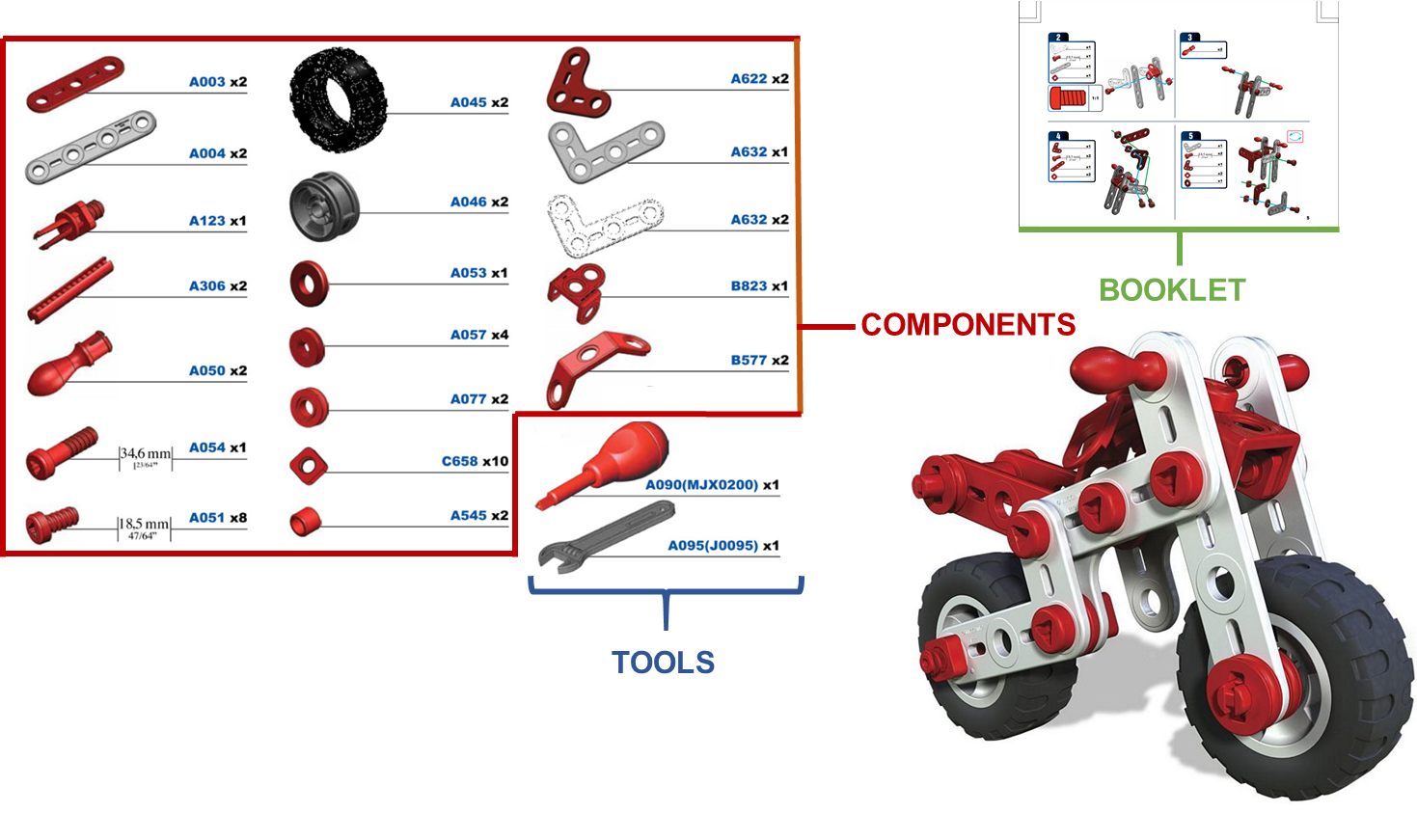
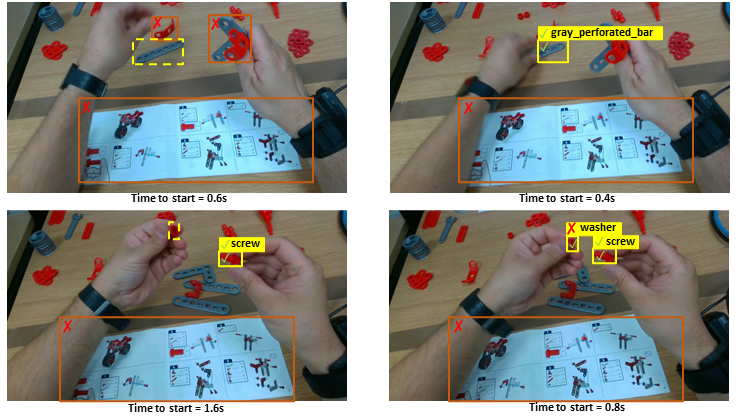
MECCANO Multimodal comprises multimodal egocentric data acquired in an industrial-like domain in which subjects built a toy model of a motorbike. The multimodality is characterized by the gaze signal, depth maps and RGB videos acquired simultaneously. We considered 20 object classes which include the 16 classes categorizing the 49 components, the two tools (screwdriver and wrench), the instructions booklet and a partial_model class.
Additional details related to the MECCANO:
- 20 different subjects in 2 countries (IT, U.K.)
- 3 modalities: RGB, Depth and Gaze
- Video Acquisition. RGB: 1920x1080 12.00 fps, Depth: 640x480 12.00 fps
- Gaze: frequency at 200Hz
- 11 training videos and 9 validation/test videos
- 8857 video segments temporally annotated indicating the verbs which describe the actions performed
- 64349 active objects annotated with bounding boxes in contact frames
- 48024 next-active objects annotated in past frames
- 89628 hands annotated with bounding boxes in past frames and contact frames
- 12 verb classes, 20 objects classes and 61 action classes
RGB Videos

RGB Frames
Depth Frames
Gaze Data
Action Temporal Annotations
EHOI Verb Temporal Annotations
Active Object Bounding Box Annotations
and frames
Hands Bounding Box Annotations
Next-Active Object Bounding Box Annotations