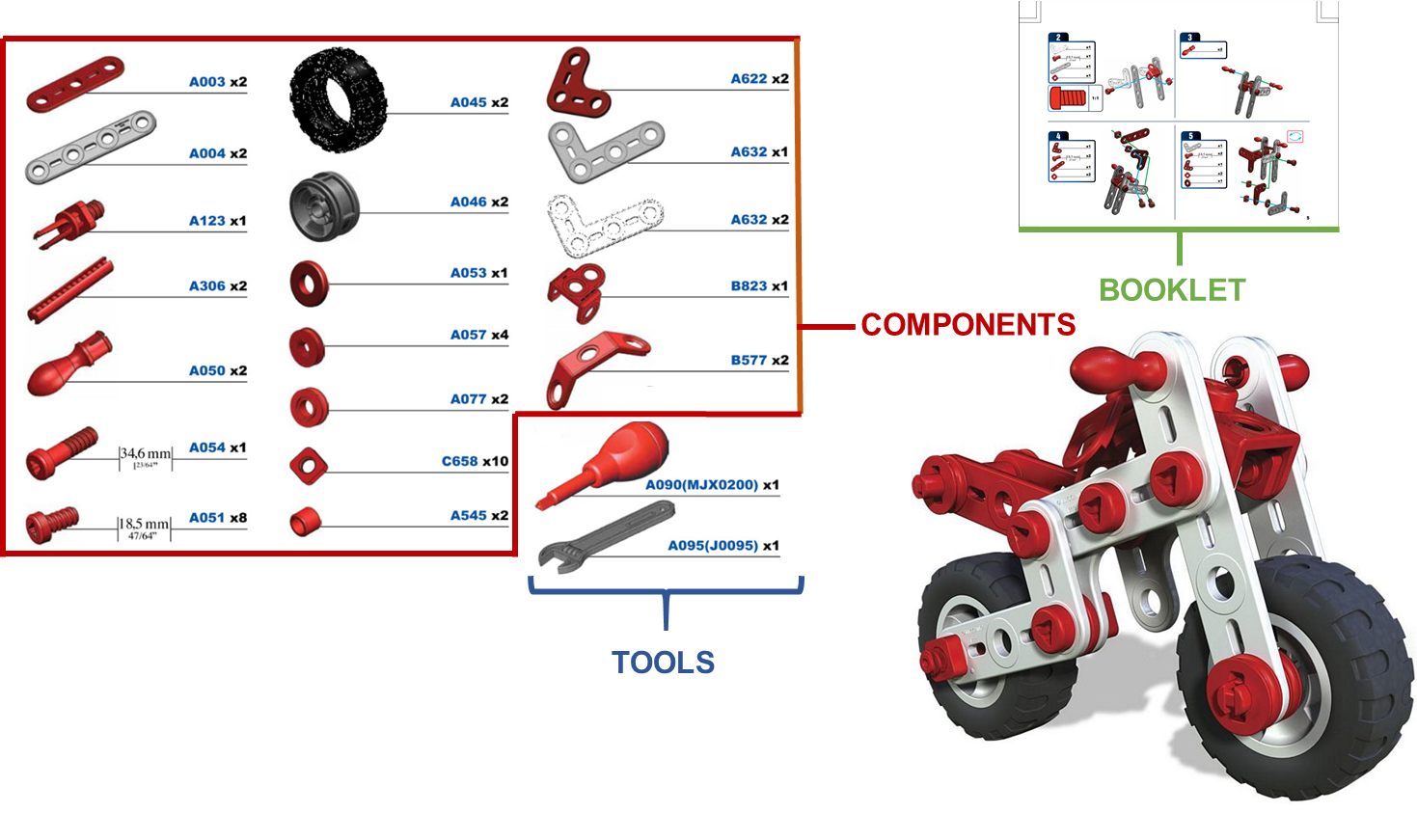
The Challenge
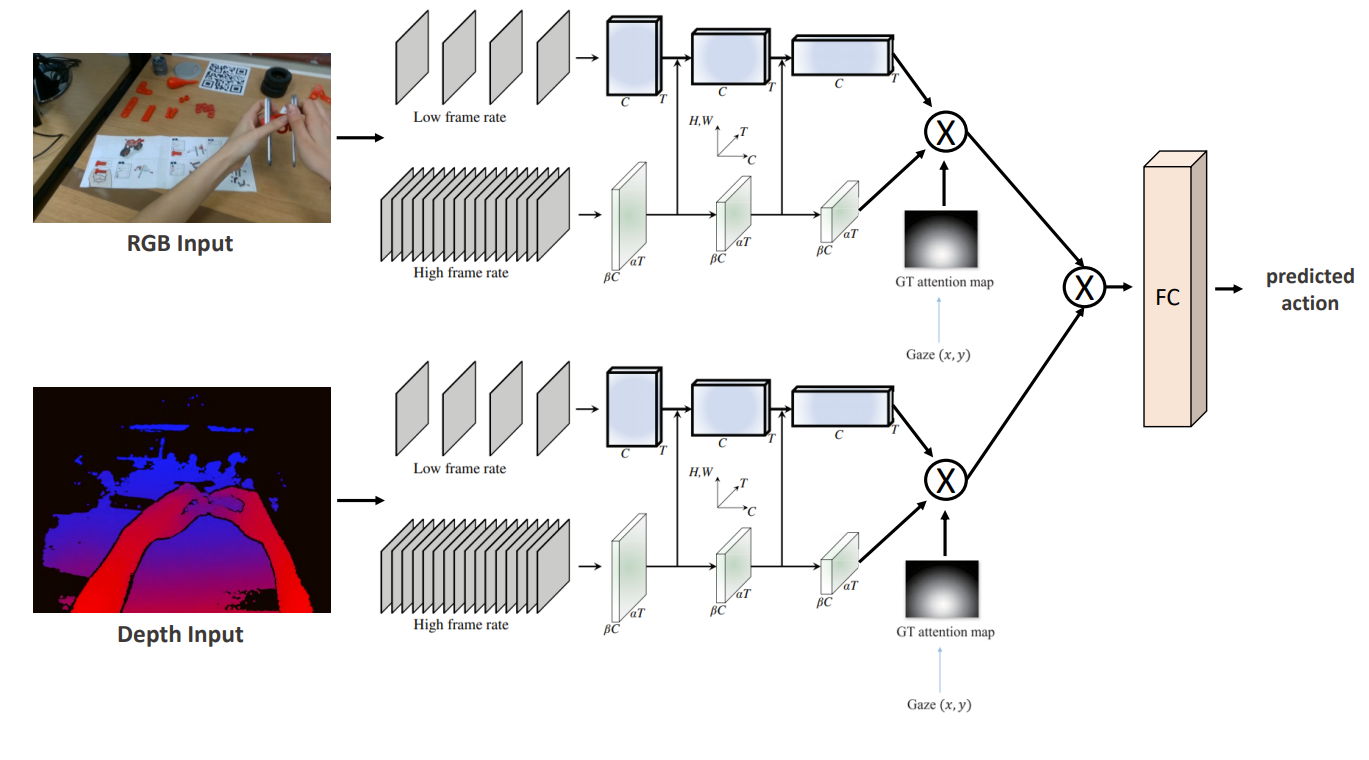
Methods are expected to take as input RGB, Depth, and Gaze signals to predict an action. Algorithms may also opt to process only a subset of these signals. The following figure shows the architecture of the baseline used to achieve this task using RGB, Depth and Gaze signals.
The participants will compete for the proposed task to obtain the best score on the provided test split of the MECCANO dataset available at the webpage of the challenge. Participants must submit their results via email to the organizers through a technical report (see emails below). Reports should evaluate action recognition using Top-1 and Top-5 accuracy computed on the whole test set. Submissions will be sorted based on Top-1 accuracy on the test split. All technical reports together with results will be published online in the web page of the challenge. The TOP-3 best results will be asked to release the code of their methods to ensure repetibility of experiments. Authors must use the ICIAP format for submitting their Tecnical Reports. The maximum number of pages is 4 excluding references.
Technical reports to participate the challenge as well as questions have to be submitted via email to the organizers: {francesco.ragusa, antonino.furnari, giovanni.farinella}@unict.it.
 1
1
 2
2 3
3