Research
DIFFERENTIABLE TASK GRAPH LEARNING: PROCEDURAL ACTIVITY REPRESENTATION AND ONLINE MISTAKE DETECTION FROM EGOCENTRIC VIDEOS
 Luigi Seminara, Giovanni Maria Farinella, Antonino Furnari (2024). Differentiable Task Graph Learning: Procedural Activity Representation and Online Mistake Detection from Egocentric Videos. In Advances in Neural Information Processing Systems.
Web Page
Luigi Seminara, Giovanni Maria Farinella, Antonino Furnari (2024). Differentiable Task Graph Learning: Procedural Activity Representation and Online Mistake Detection from Egocentric Videos. In Advances in Neural Information Processing Systems.
Web Page
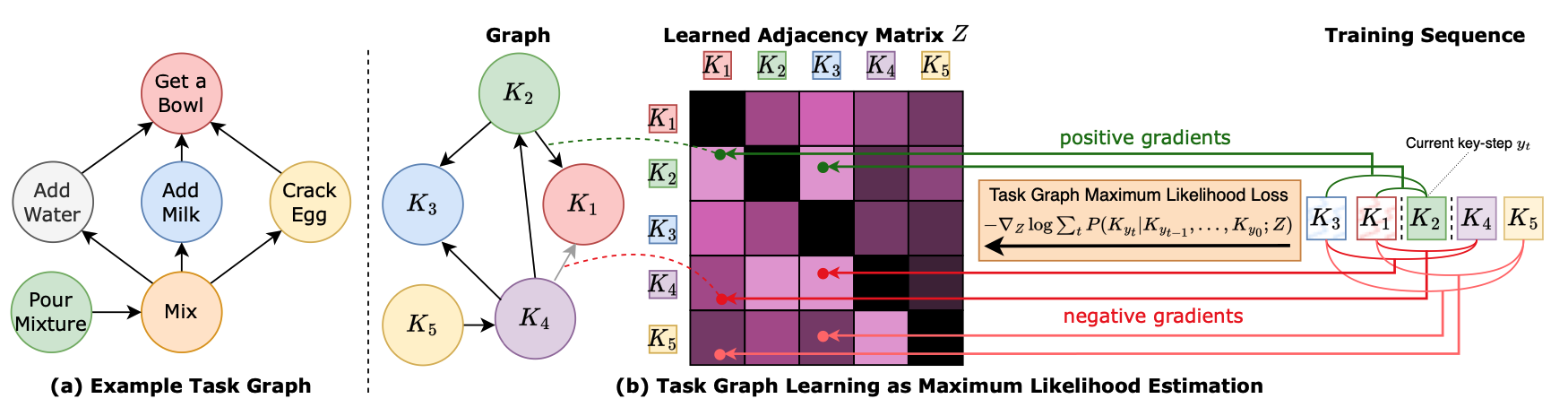
Procedural activities are sequences of key-steps aimed at achieving specific goals. They are crucial to build intelligent agents able to assist users effectively. In this context, task graphs have emerged as a human-understandable representation of procedural activities, encoding a partial ordering over the key-steps. While previous works generally relied on hand-crafted procedures to extract task graphs from videos, in this paper, we propose an approach based on direct maximum likelihood optimization of edges’ weights, which allows gradient-based learning of task graphs and can be naturally plugged into neural network architectures. Experiments on the CaptainCook4D dataset demonstrate the ability of our approach to predict accurate task graphs from the observation of action sequences, with an improvement of +16.7% over previous approaches. Owing to the differentiability of the proposed framework, we also introduce a feature-based approach, aiming to predict task graphs from key-step textual or video embeddings, for which we observe emerging video understanding abilities. Task graphs learned with our approach are also shown to significantly enhance online mistake detection in procedural egocentric videos, achieving notable gains of +19.8% and +7.5% on the Assembly101 and EPIC-Tent datasets. Code for replicating experiments will be publicly released.
AFF-TTENTION! AFFORDANCES AND ATTENTION MODELS FOR SHORT-TERM OBJECT INTERACTION ANTICIPATION
 Lorenzo Mur-Labadia, Ruben Martinez-Cantin, Josechu Guerrero, Giovanni Maria Farinella, Antonino Furnari (2024). AFF-ttention! Affordances and Attention models for Short-Term Object Interaction Anticipation. In European Conference on Computer Vision (ECCV).
Web Page
Lorenzo Mur-Labadia, Ruben Martinez-Cantin, Josechu Guerrero, Giovanni Maria Farinella, Antonino Furnari (2024). AFF-ttention! Affordances and Attention models for Short-Term Object Interaction Anticipation. In European Conference on Computer Vision (ECCV).
Web Page
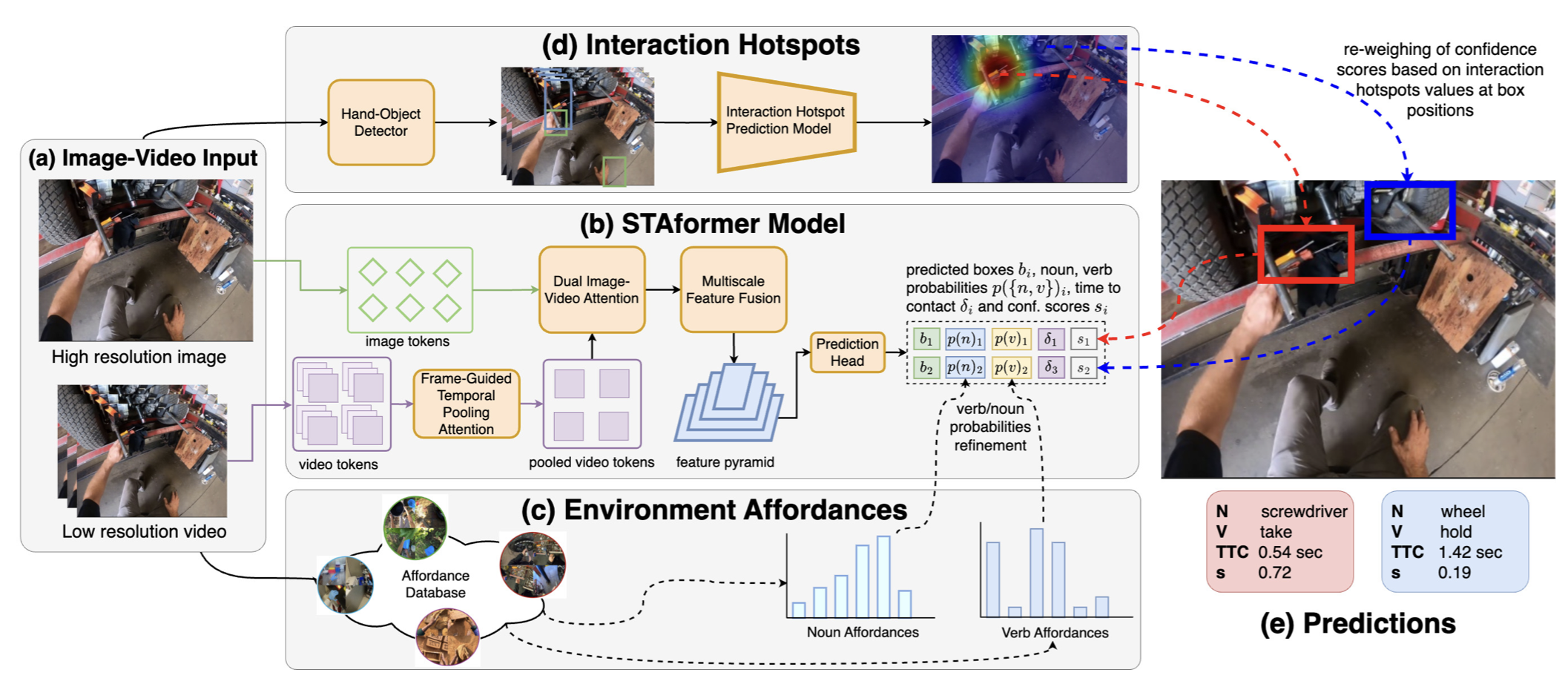
Short-Term object-interaction Anticipation consists of detecting the location of the next-active objects, the noun and verb categories of the interaction, and the time to contact from the observation of egocentric video. This ability is fundamental for wearable assistants or human robot interaction to understand the user goals, but there is still room for improvement to perform STA in a precise and reliable way. In this work, we improve the performance of STA predictions with two contributions: 1. We propose STAformer, a novel attention-based architecture integrating frame guided temporal pooling, dual image-video attention, and multiscale feature fusion to support STA predictions from an image-input video pair. 2. We introduce two novel modules to ground STA predictions on human behavior by modeling affordances.First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. Our results show significant relative Overall Top-5 mAP improvements of up to +45% on Ego4D and +42% on a novel set of curated EPIC-Kitchens STA labels. We will release the code, annotations, and pre extracted affordances on Ego4D and EPIC- Kitchens to encourage future research in this area.
SYNCHRONIZATION IS ALL YOU NEED: EXOCENTRIC-TO-EGOCENTRIC TRANSFER FOR TEMPORAL ACTION SEGMENTATION WITH UNLABELED SYNCHRONIZED VIDEO PAIRS
 Camillo Quattrocchi, Antonino Furnari, Daniele Di Mauro, Mario Valerio Giuffrida, Giovanni Maria Farinella (2024). Synchronization is All You Need: Exocentric-to-Egocentric Transfer for Temporal Action Segmentation with Unlabeled Synchronized Video Pairs In European Conference on Computer Vision (ECCV).
Web Page
Camillo Quattrocchi, Antonino Furnari, Daniele Di Mauro, Mario Valerio Giuffrida, Giovanni Maria Farinella (2024). Synchronization is All You Need: Exocentric-to-Egocentric Transfer for Temporal Action Segmentation with Unlabeled Synchronized Video Pairs In European Conference on Computer Vision (ECCV).
Web Page
We consider the problem of transferring a temporal action segmentation system initially designed for exocentric (fixed) cameras to an egocentric scenario, where wearable cameras capture video data. The conventional supervised approach requires the collection and labeling of a new set of egocentric videos to adapt the model, which is costly and time-consuming. Instead, we propose a novel methodology which performs the adaptation leveraging existing labeled exocentric videos and a new set of unlabeled, synchronized exocentric-egocentric video pairs, for which temporal action segmentation annotations do not need to be collected. We implement the proposed methodology with an approach based on knowledge distillation, which we investigate both at the feature and Temporal Action Segmentation model level. Experiments on Assembly101 and EgoExo4D demonstrate the effectiveness of the proposed method against classic unsupervised domain adaptation and temporal alignment approaches. Without bells and whistles, our best model performs on par with supervised approaches trained on labeled egocentric data, without ever seeing a single egocentric label, achieving a +15.99 improvement in the edit score (28.59 vs 12.60) on the Assembly101 dataset compared to a baseline model trained solely on exocentric data. In similar settings, our method also improves edit score by +3.32 on the challenging EgoExo4D benchmark.
ARE SYNTHETIC DATA USEFUL FOR EGOCENTRIC HAND-OBJECT INTERACTION DETECTION?
 Rosario Leonardi, Antonino Furnari, Francesco Ragusa, Giovanni Maria Farinella (2024). Are Synthetic Data Useful for Egocentric Hand-Object Interaction Detection?. In European Conference on Computer Vision (ECCV).
Web Page
Rosario Leonardi, Antonino Furnari, Francesco Ragusa, Giovanni Maria Farinella (2024). Are Synthetic Data Useful for Egocentric Hand-Object Interaction Detection?. In European Conference on Computer Vision (ECCV).
Web Page
In this study, we investigate the effectiveness of synthetic data in enhancing egocentric hand-object interaction detection. Via extensive experiments and comparative analyses on three egocentric datasets, VISOR, EgoHOS, and ENIGMA-51, our findings reveal how to exploit synthetic data for the HOI detection task when real labeled data are scarce or unavailable. Specifically, by leveraging only 10% of real labeled data, we achieve improvements in Overall AP compared to baselines trained exclusively on real data of: +5.67% on EPIC-KITCHENS VISOR, +8.24% on EgoHOS, and +11.69% on ENIGMA-51. Our analysis is supported by a novel data generation pipeline and the newly introduced HOI-Synth benchmark which augments existing datasets with synthetic images of hand-object interactions automatically labeled with hand-object contact states, bounding boxes, and pixel-wise segmentation masks. We publicly release the generated data, code, and data generation tools to support future research.
PREGO: ONLINE MISTAKE DETECTION IN PROCEDURAL EGOCENTRIC VIDEOS
 Alessandro Flaborea, Guido D'Amely, Leonardo Plini, Luca Scofano, Edoardo De Matteis, Antonino Furnari, Giovanni Maria Farinella, Fabio Galasso (2024). PREGO: online mistake detection in PRocedural EGOcentric videos. In Conference on Computer Vision and Pattern Recognition (CVPR).
Web Page
Alessandro Flaborea, Guido D'Amely, Leonardo Plini, Luca Scofano, Edoardo De Matteis, Antonino Furnari, Giovanni Maria Farinella, Fabio Galasso (2024). PREGO: online mistake detection in PRocedural EGOcentric videos. In Conference on Computer Vision and Pattern Recognition (CVPR).
Web Page
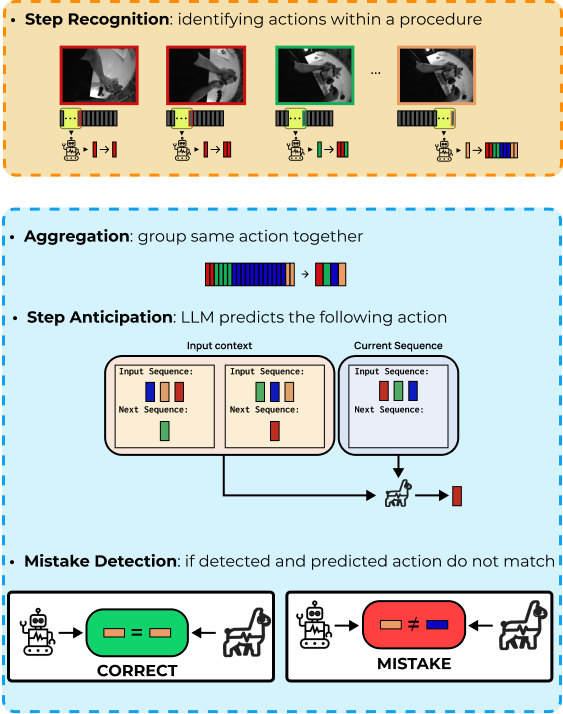
Promptly identifying procedural errors from egocentric videos in an online setting is highly challenging and valuable for detecting mistakes as soon as they happen. This capability has a wide range of applications across various fields, such as manufacturing and healthcare. The nature of procedural mistakes is open-set since novel types of failures might occur, which calls for one-class classifiers trained on correctly executed procedures. However, no technique can currently detect open-set procedural mistakes online. We propose PREGO, the first online one-class classification model for mistake detection in PRocedural EGOcentric videos. PREGO is based on an online action recognition component to model the current action, and a symbolic reasoning module to predict the next actions. Mistake detection is performed by comparing the recognized current action with the expected future one. We evaluate PREGO on two procedural egocentric video datasets, Assembly101 and Epic-tent, which we adapt for online benchmarking of procedural mistake detection to establish suitable benchmarks, thus defining the Assembly101-O and Epic-tent-O datasets, respectively.
ACTION SCENE GRAPHS FOR LONG-FORM UNDERSTANDING OF EGOCENTRIC VIDEOS
 Ivan Rodin, Antonino Furnari, Kyle Min, Subarna Tripathi, Giovanni Maria Farinella (2024). Action Scene Graphs for Long-Form Understanding of Egocentric Videos. In Conference on Computer Vision and Pattern Recognition (CVPR).
Web_Page
Ivan Rodin, Antonino Furnari, Kyle Min, Subarna Tripathi, Giovanni Maria Farinella (2024). Action Scene Graphs for Long-Form Understanding of Egocentric Videos. In Conference on Computer Vision and Pattern Recognition (CVPR).
Web_Page
We present Egocentric Action Scene Graphs (EASGs), a new representation for long-form understanding of egocentric videos. EASGs extend standard manually-annotated representations of egocentric videos, such as verb-noun action labels, by providing a temporally evolving graphbased description of the actions performed by the camera wearer, including interacted objects, their relationships, and how actions unfold in time. Through a novel annotation procedure, we extend the Ego4D dataset by adding manually labeled Egocentric Action Scene Graphs offering a rich set of annotations designed for long-from egocentric video understanding. We hence define the EASG generation task and provide a baseline approach, establishing preliminary benchmarks. Experiments on two downstream tasks, egocentric action anticipation and egocentric activity summarization, highlight the effectiveness of EASGs for long-form egocentric video understanding.
EGO-EXO4D
 Carnegie Mellon University Pittsburgh, Università di Catania, Universidad de los Andes, Carnegie Mellon University Africa, The University of Tokyo, Simon Fraser University, King Abdullah University of Science and Technology, University of Bristol, Meta, University of Minnesota, International Institute of Information Technology Hyderabad, National University of Singapore, Indiana University Bloomington, Georgia Institute of Technology, The University of North Carolina at Chapel Hill, University of Pennsylvania, The University of Texas at Austin, University of Illinois Urbana-Champaign.
Web Page
Carnegie Mellon University Pittsburgh, Università di Catania, Universidad de los Andes, Carnegie Mellon University Africa, The University of Tokyo, Simon Fraser University, King Abdullah University of Science and Technology, University of Bristol, Meta, University of Minnesota, International Institute of Information Technology Hyderabad, National University of Singapore, Indiana University Bloomington, Georgia Institute of Technology, The University of North Carolina at Chapel Hill, University of Pennsylvania, The University of Texas at Austin, University of Illinois Urbana-Champaign.
Web Page
 Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Mohaiminul Islam, Suyog Jain, Rawal Khirodkar, Devansh Kukreja, Kevin J Liang, Jia-Wei Liu, Sagnik Majumder, Yongsen Mao, Miguel Martin, Effrosyni Mavroudi, Tushar Nagarajan, Francesco Ragusa, Santhosh Kumar Ramakrishnan, Luigi Seminara, Arjun Somayazulu, Yale Song, Shan Su, Zihui Xue, Edward Zhang, Jinxu Zhang, Angela Castillo, Changan Chen, Xinzhu Fu, Ryosuke Furuta, Cristina Gonzalez, Prince Gupta, Jiabo Hu, Yifei Huang, Yiming Huang, Weslie Khoo, Anush Kumar, Robert Kuo, Sach Lakhavani, Miao Liu, Mi Luo, Zhengyi Luo, Brighid Meredith, Austin Miller, Oluwatumininu Oguntola, Xiaqing Pan, Penny Peng, Shraman Pramanick, Merey Ramazanova, Fiona Ryan, Wei Shan, Kiran Somasundaram, Chenan Song, Audrey Southerland, Masatoshi Tateno, Huiyu Wang, Yuchen Wang, Takuma Yagi, Mingfei Yan, Xitong Yang, Zecheng Yu, Shengxin Cindy Zha, Chen Zhao, Ziwei Zhao, Zhifan Zhu, Jeff Zhuo, Pablo Arbelaez, Gedas Bertasius, David Crandall, Dima Damen, Jakob Engel, Giovanni Maria Farinella, Antonino Furnari, Bernard Ghanem, Judy Hoffman, C. V. Jawahar, Richard Newcombe, Hyun Soo Park, James M. Rehg, Yoichi Sato, Manolis Savva, Jianbo Shi, Mike Zheng Shou, Michael Wray (2024). Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives. In Conference on Computer Vision and Pattern Recognition (CVPR).
Web_Page
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Mohaiminul Islam, Suyog Jain, Rawal Khirodkar, Devansh Kukreja, Kevin J Liang, Jia-Wei Liu, Sagnik Majumder, Yongsen Mao, Miguel Martin, Effrosyni Mavroudi, Tushar Nagarajan, Francesco Ragusa, Santhosh Kumar Ramakrishnan, Luigi Seminara, Arjun Somayazulu, Yale Song, Shan Su, Zihui Xue, Edward Zhang, Jinxu Zhang, Angela Castillo, Changan Chen, Xinzhu Fu, Ryosuke Furuta, Cristina Gonzalez, Prince Gupta, Jiabo Hu, Yifei Huang, Yiming Huang, Weslie Khoo, Anush Kumar, Robert Kuo, Sach Lakhavani, Miao Liu, Mi Luo, Zhengyi Luo, Brighid Meredith, Austin Miller, Oluwatumininu Oguntola, Xiaqing Pan, Penny Peng, Shraman Pramanick, Merey Ramazanova, Fiona Ryan, Wei Shan, Kiran Somasundaram, Chenan Song, Audrey Southerland, Masatoshi Tateno, Huiyu Wang, Yuchen Wang, Takuma Yagi, Mingfei Yan, Xitong Yang, Zecheng Yu, Shengxin Cindy Zha, Chen Zhao, Ziwei Zhao, Zhifan Zhu, Jeff Zhuo, Pablo Arbelaez, Gedas Bertasius, David Crandall, Dima Damen, Jakob Engel, Giovanni Maria Farinella, Antonino Furnari, Bernard Ghanem, Judy Hoffman, C. V. Jawahar, Richard Newcombe, Hyun Soo Park, James M. Rehg, Yoichi Sato, Manolis Savva, Jianbo Shi, Mike Zheng Shou, Michael Wray (2024). Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives. In Conference on Computer Vision and Pattern Recognition (CVPR).
Web_Page
Ego-Exo4D presents three meticulously synchronized natural language datasets paired with videos. (1) expert commentary, revealing nuanced skills. (2) participant-provided narrate-and-act descriptions in a tutorial style. (3) one-sentence atomic action descriptions to support browsing, mining the dataset, and addressing challenges in video-language learning. Our goal is to capture simultaneous ego and multiple exo videos, together with multiple egocentric sensing modalities. Our camera configuration features Aria glasses for ego capture, including an 8 MP RGB camera and two SLAM cameras. The ego camera is calibrated and time-synchronized with 4-5 (stationary) GoPros as the exo capture devices. The number and placement of the exocentric cameras is determined per scenario in order to allow maximal coverage of useful viewpoints without obstructing the participants’ activity. Apart from multiple views, we also capture multiple modalities:
- An array of seven microphones
- Two IMUs (800 Hz and 1000 Hz respectively), a barometer (50 fps) and a magnetometer (10 fps).
- And from Aria Machine Perception Services (MPS) we get:
- Aria 6 DoF Localization
- Eye Gaze
- Point Clouds
- GoPro 6 DoF Localization.
Along with the dataset, we introduce four benchmarks. The recognition benchmark aims to recognize individual keysteps and infer their relation in the execution of procedural activities. The proficiency estimation benchmark aims to estimate the camera wearer's skills. The relation benchmark focuses on methods to establish spatial relationships between synchronized multi-view frames. The pose estimation benchmarks concerns the estimation of the camera pose of the camera wearer.
EGO4D
 Grauman, Westbury, Byrne, Chavis, Furnari, Girdhar, Hamburger, Jiang, Liu, Liu, Martin, Nagarajan, Radosavovic, Ramakrishnan, Ryan, Sharma, Wray, Xu, Xu, Zhao, Bansal, Batra, Cartillier, Crane, Do, Doulaty, Erapalli, Feichtenhofer, Fragomeni, Fu, Fuegen, Gebreselasie, Gonzalez, Hillis, Huang, Huang, Jia, Khoo, Kolar, Kottur, Kumar, Landini, Li, Li, Li, Mangalam, Modhugu, Munro, Murrell, Nishiyasu, Price, Puentes, Ramazanova, Sari, Somasundaram, Southerland, Sugano, Tao, Vo, Wang, Wu, Yagi, Zhu, Arbelaez, Crandall, Damen, Farinella, Ghanem, Ithapu, Jawahar, Joo, Kitani, Li, Newcombe, Oliva, Park, Rehg, Sato, Shi, Shou, Torralba, Torresani, Yan, Malik ( 2022 ). Around the World in 3,000 Hours of Egocentric Video . In IEEE/CVF International Conference on Computer Vision and Pattern Recognition.
Web Page
Grauman, Westbury, Byrne, Chavis, Furnari, Girdhar, Hamburger, Jiang, Liu, Liu, Martin, Nagarajan, Radosavovic, Ramakrishnan, Ryan, Sharma, Wray, Xu, Xu, Zhao, Bansal, Batra, Cartillier, Crane, Do, Doulaty, Erapalli, Feichtenhofer, Fragomeni, Fu, Fuegen, Gebreselasie, Gonzalez, Hillis, Huang, Huang, Jia, Khoo, Kolar, Kottur, Kumar, Landini, Li, Li, Li, Mangalam, Modhugu, Munro, Murrell, Nishiyasu, Price, Puentes, Ramazanova, Sari, Somasundaram, Southerland, Sugano, Tao, Vo, Wang, Wu, Yagi, Zhu, Arbelaez, Crandall, Damen, Farinella, Ghanem, Ithapu, Jawahar, Joo, Kitani, Li, Newcombe, Oliva, Park, Rehg, Sato, Shi, Shou, Torralba, Torresani, Yan, Malik ( 2022 ). Around the World in 3,000 Hours of Egocentric Video . In IEEE/CVF International Conference on Computer Vision and Pattern Recognition.
Web Page
Ego4D is a massive-scale Egocentric dataset of unprecedented diversity. It consists of 3,670 hours of video collected by 923 unique participants from 74 worldwide locations in 9 different countries. The project brings together 88 researchers, in an international consortium, to dramatically increases the scale of egocentric data publicly available by an order of magnitude, making it more than 20x greater than any other data set in terms of hours of footage. Ego4D aims to catalyse the next era of research in first-person visual perception. The dataset is diverse in its geographic coverage, scenarios, participants and captured modalities. We consulted a survey from the U.S. Bureau of Labor Statistics that captures how people spend the bulk of their time. Data was captured using seven different off-the-shelf head-mounted cameras: GoPro, Vuzix Blade, Pupil Labs, ZShades, OR- DRO EP6, iVue Rincon 1080, and Weeview. In addition to video, portions of Ego4D offer other data modalities: 3D scans, audio, gaze, stereo, multiple synchronized wearable cameras, and textual narrations.
VISUAL OBJECT TRACKING IN FIRST PERSON VISION
![]() Matteo Dunnhofer, Antonino Furnari, Giovanni Maria Farinella, Christian Micheloni (2022). Visual Object Tracking in First Person Vision. International Journal of Computer Vision (IJCV).
Web Page
Matteo Dunnhofer, Antonino Furnari, Giovanni Maria Farinella, Christian Micheloni (2022). Visual Object Tracking in First Person Vision. International Journal of Computer Vision (IJCV).
Web Page
The understanding of human-object interactions is fundamental in First Person Vision (FPV). Visual tracking algorithms which follow the objects manipulated by the camera wearer can provide useful information to effectively model such interactions. In the last years, the computer vision community has significantly improved the performance of tracking algorithms for a large variety of target objects and scenarios. Despite a few previous attempts to exploit trackers in the FPV domain, a methodical analysis of the performance of state-of-the-art trackers is still missing. This research gap raises the question of whether current solutions can be used ``off-the-shelf'' or more domain-specific investigations should be carried out. This paper aims to provide answers to such questions. We present the first systematic investigation of single object tracking in FPV. Our study extensively analyses the performance of 42 algorithms including generic object trackers and baseline FPV-specific trackers. The analysis is carried out by focusing on different aspects of the FPV setting, introducing new performance measures, and in relation to FPV-specific tasks. The study is made possible through the introduction of TREK-150, a novel benchmark dataset composed of 150 densely annotated video sequences. Our results show that object tracking in FPV poses new challenges to current visual trackers. We highlight the factors causing such behavior and point out possible research directions. Despite their difficulties, we prove that trackers bring benefits to FPV downstream tasks requiring short-term object tracking. We expect that generic object tracking will gain popularity in FPV as new and FPV-specific methodologies are investigated.
THE MECCANO DATASET
 Francesco Ragusa, Antonino Furnari, Salvatore Livatino, Giovanni Maria Farinella (2021). The MECCANO Dataset: Understanding Human-Object Interactions from Egocentric Videos in an Industrial-like Domain. In IEEE Winter Conference on Application of Computer Vision (WACV).
Web Page
Francesco Ragusa, Antonino Furnari, Salvatore Livatino, Giovanni Maria Farinella (2021). The MECCANO Dataset: Understanding Human-Object Interactions from Egocentric Videos in an Industrial-like Domain. In IEEE Winter Conference on Application of Computer Vision (WACV).
Web Page
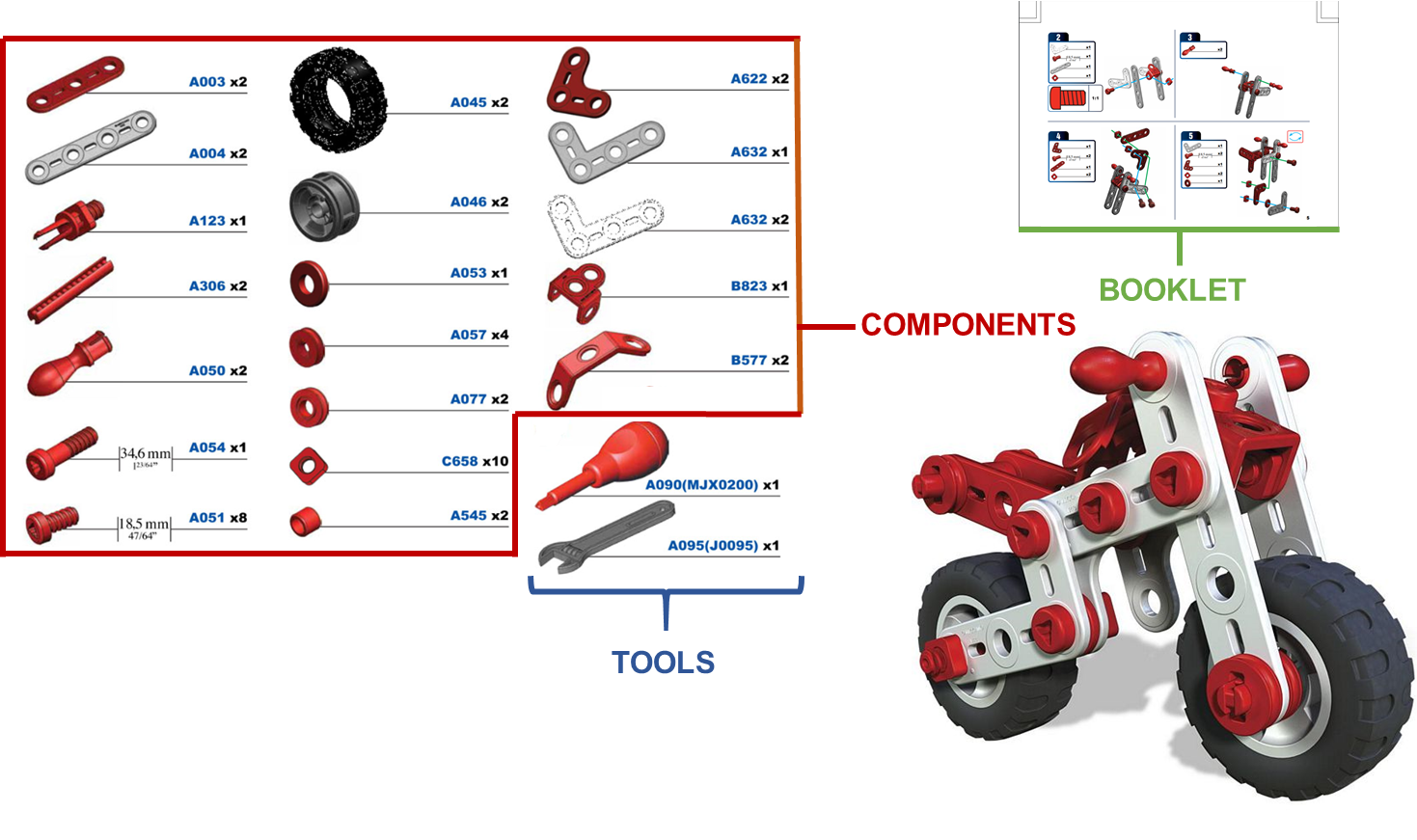
We introduce MECCANO, the first dataset of egocentric videos to study human-object interactions in industrial-like settings. MECCANO has been acquired by 20 participants who were asked to build a motorbike model, for which they had to interact with tiny objects and tools. The dataset has been explicitly labeled for the task of recognizing human-object interactions from an egocentric perspective. Specifically, each interaction has been labeled both temporally (with action segments) and spatially (with active object bounding boxes). With the proposed dataset, we investigate four different tasks including 1) action recognition, 2) active object detection, 3) active object recognition and 4) egocentric human-object interaction detection, which is a revisited version of the standard human-object interaction detection task. Baseline results show that the MECCANO dataset is a challenging benchmark to study egocentric human-object interactions in industrial-like scenarios.
Rolling-Unrolling LSTM for Egocentric Action Anticipation
 A. Furnari, G. M. Farinella, What Would You Expect? Anticipating Egocentric Actions with Rolling-Unrolling LSTMs and Modality Attention, International Conference on Computer Vision, 2019.
Web Page
A. Furnari, G. M. Farinella, What Would You Expect? Anticipating Egocentric Actions with Rolling-Unrolling LSTMs and Modality Attention, International Conference on Computer Vision, 2019.
Web Page
Egocentric action anticipation consists in understanding which objects the camera wearer will interact with in the near future and which actions they will perform. We tackle the problem proposing an architecture able to anticipate actions at multiple temporal scales using two LSTMs to 1) summarize the past, and 2) formulate predictions about the future. The input video is processed considering three complimentary modalities: appearance (RGB), motion (optical flow) and objects (object-based features). Modality-specific predictions are fused using a novel Modality ATTention (MATT) mechanism which learns to weigh modalities in an adaptive fashion. Extensive evaluations on two large-scale benchmark datasets show that our method outperforms prior art by up to +7% on the challenging EPIC-KITCHENS dataset including more than 2500 actions, and generalizes to EGTEA Gaze+. Our approach is also shown to generalize to the tasks of early action recognition and action recognition.
EPIC-Kitchens
 D. Damen, H. Doughty, , G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, M. Wray, Scaling Egocentric Vision: The EPIC-KITCHENS Dataset, European Conference on Computer Vision, 2018.
Web Page
D. Damen, H. Doughty, , G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, M. Wray, Scaling Egocentric Vision: The EPIC-KITCHENS Dataset, European Conference on Computer Vision, 2018.
Web Page
We introduce EPIC-KITCHENS, a large-scale egocentric video benchmark recorded by 32 participants in their native kitchen environments. Our videos depict nonscripted daily activities. Recording took place in 4 cities (in North America and Europe) by participants belonging to 10 different nationalities, resulting in highly diverse kitchen habits and cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labeled for a total of 39.6K action segments and 454.2K object bounding boxes. We describe our object, action and anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens.
Egocentric Shopping Cart Localization
 E. Spera, A. Furnari, S. Battiato, G. M. Farinella. Egocentric Shopping Cart Localization . In International Conference on Pattern Recognition (ICPR). 2018.
Web Page
E. Spera, A. Furnari, S. Battiato, G. M. Farinella. Egocentric Shopping Cart Localization . In International Conference on Pattern Recognition (ICPR). 2018.
Web Page
We investigate the new problem of egocentric shopping cart localization in retail stores. We propose a novel large-scale dataset for image-based egocentric shopping cart localization. The dataset has been collected using cameras placed on shopping carts in a large retail store. It contains a total of 19,531 image frames, each labelled with its six Degrees Of Freedom pose. We study the localization problem by analysing how cart locations should be represented and estimated, and how to assess the localization results. We benchmark two families of algorithms: classic methods based on image retrieval and emerging methods based on regression.
Vision For Autonomous Navigation

Organizing Egocentric Videos of Daily Living Activities
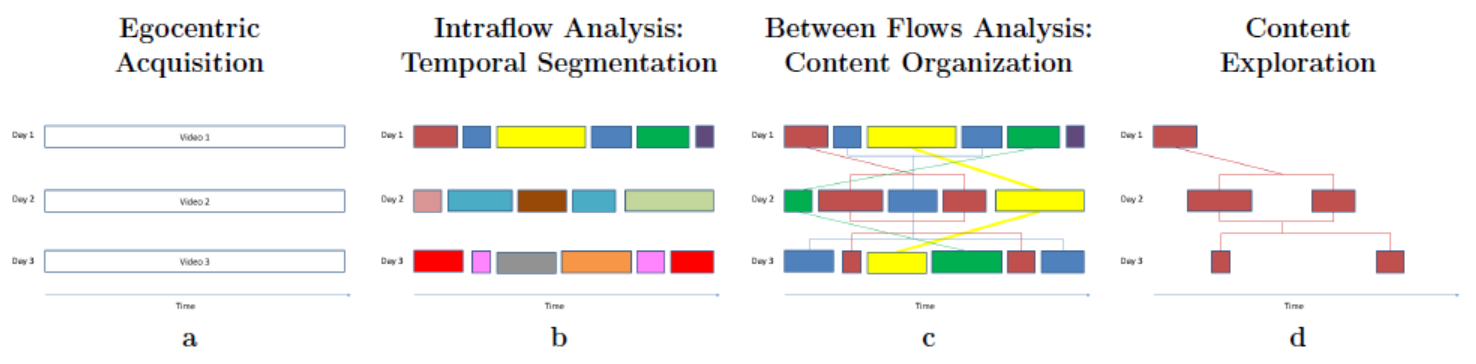 A. Ortis, G. M. Farinella, V. D’Amico, L. Addesso, G. Torrisi, S. Battiato. Organizing egocentric videos of daily living activities. Pattern Recognition, 72(Supplement C), pp. 207 - 218. 2017.
Web Page
A. Ortis, G. M. Farinella, V. D’Amico, L. Addesso, G. Torrisi, S. Battiato. Organizing egocentric videos of daily living activities. Pattern Recognition, 72(Supplement C), pp. 207 - 218. 2017.
Web Page
We propose a system useful for the automatic organization of the egocentric videos acquired by a user over different days. The system is able to perform an unsupervised segmentation of each egocentric video in chapters by considering visual content. The video segments related to the different days are hence linked to produce graphs which are coherent with respect to the context in which the user acts.
Evaluation of Egocentric Action Recognition
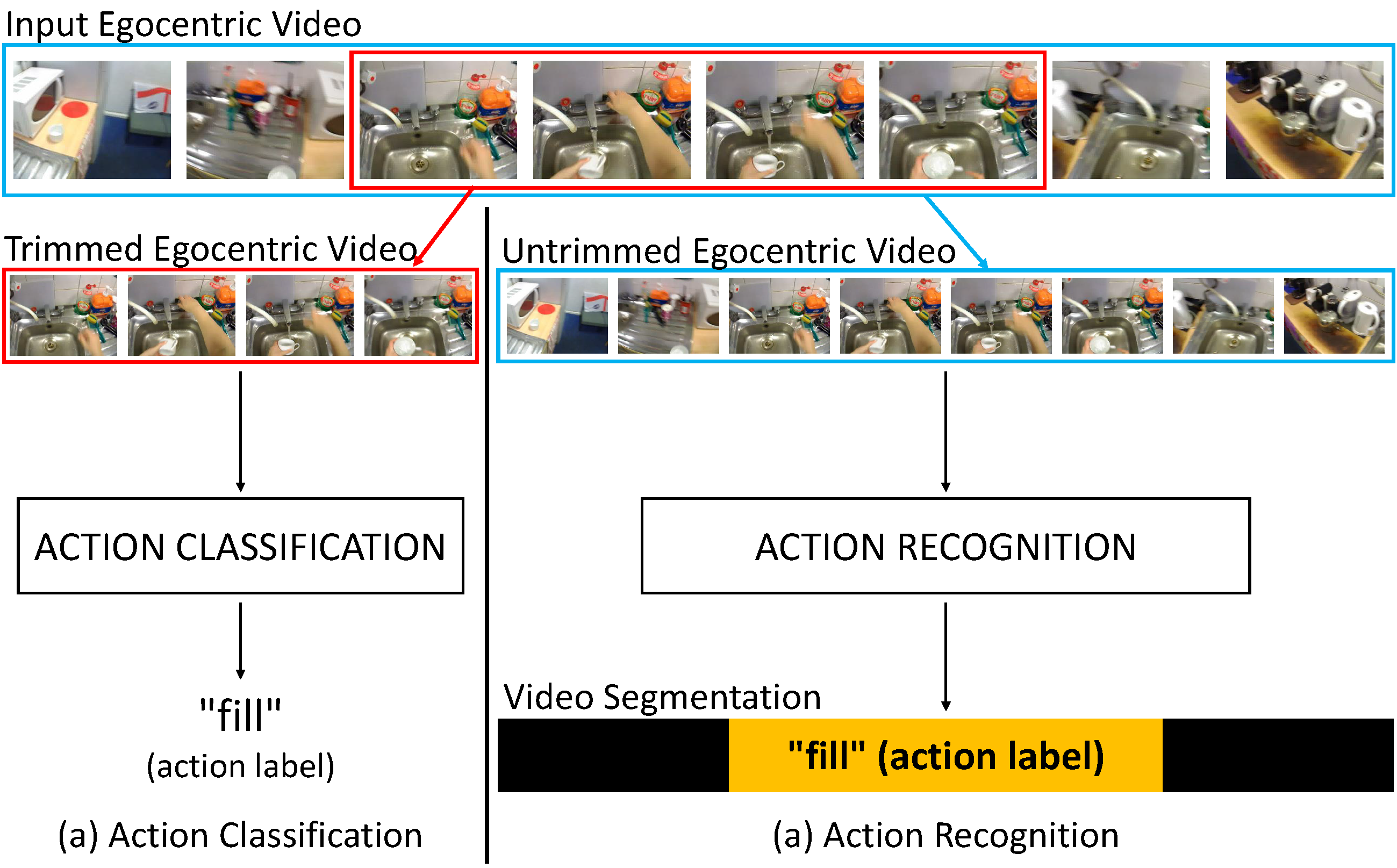 A. Furnari, S. Battiato, G. M. Farinella, "How Shall We Evaluate Egocentric Action Recognition?", In International Workshop on Egocentric Perception, Interaction and Computing (EPIC) in conjunction with ICCV, 2017.
Web Page
A. Furnari, S. Battiato, G. M. Farinella, "How Shall We Evaluate Egocentric Action Recognition?", In International Workshop on Egocentric Perception, Interaction and Computing (EPIC) in conjunction with ICCV, 2017.
Web Page
We propose a set of measures aimed to quantitatively and qualitatively assess the performance of egocentric action recognition methods. To improve exploitability of current action classification methods in the recognition scenario, we investigate how frame-wise predictions can be turned into action-based temporal video segmentations. Experiments on both synthetic and real data show that the proposed set of measures can help to improve evaluation and to drive the design of egocentric action recognition methods.
Next Active Object Prediction from Egocentric Video
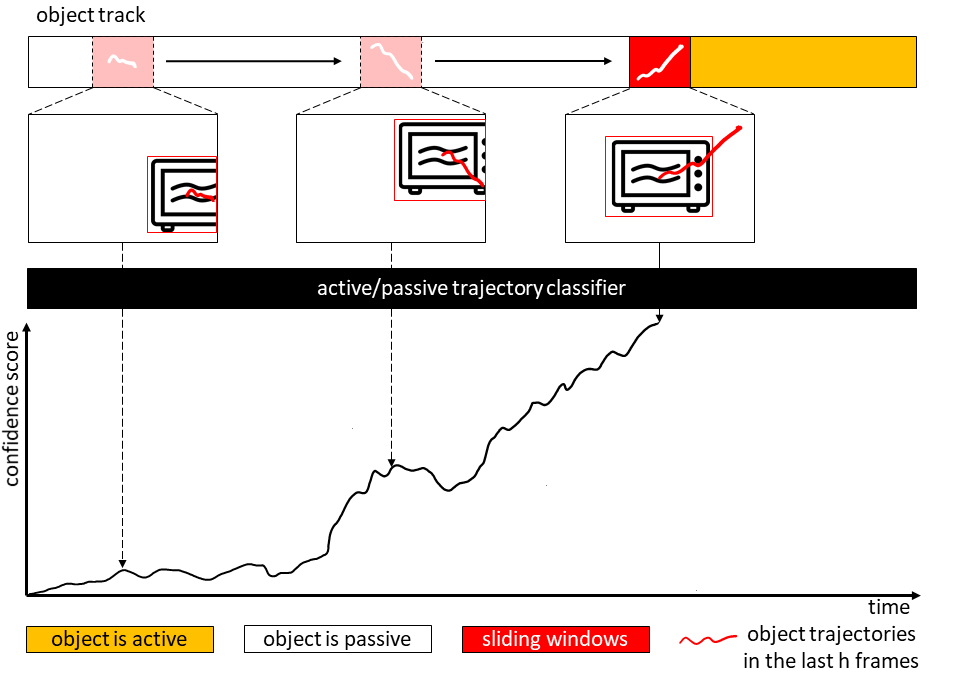 A. Furnari, S. Battiato, K. Grauman, G. M. Farinella, Next-Active-Object Prediction from Egocentric Videos, Journal of Visual Communication and Image Representation, Volume 49, November 2017, Pages 401-411, 2017 Web Page
A. Furnari, S. Battiato, K. Grauman, G. M. Farinella, Next-Active-Object Prediction from Egocentric Videos, Journal of Visual Communication and Image Representation, Volume 49, November 2017, Pages 401-411, 2017 Web Page
We address the problem of recognizing next-active-objects from egocentric videos. Even if this task is not trivial, the First Person Vision paradigm can provide important cues useful to address this challenge. Specifically, we propose to exploit the dynamics of the scene to recognize next-active-objects before an object interaction actually begins. Next-active-object prediction is performed by analyzing fixed-length trajectory segments within a sliding window. We investigate what properties of egocentric object motion are most discriminative for the task and evaluate the temporal support with respect to which such motion should be considered.
Visual Market Basket Analysis
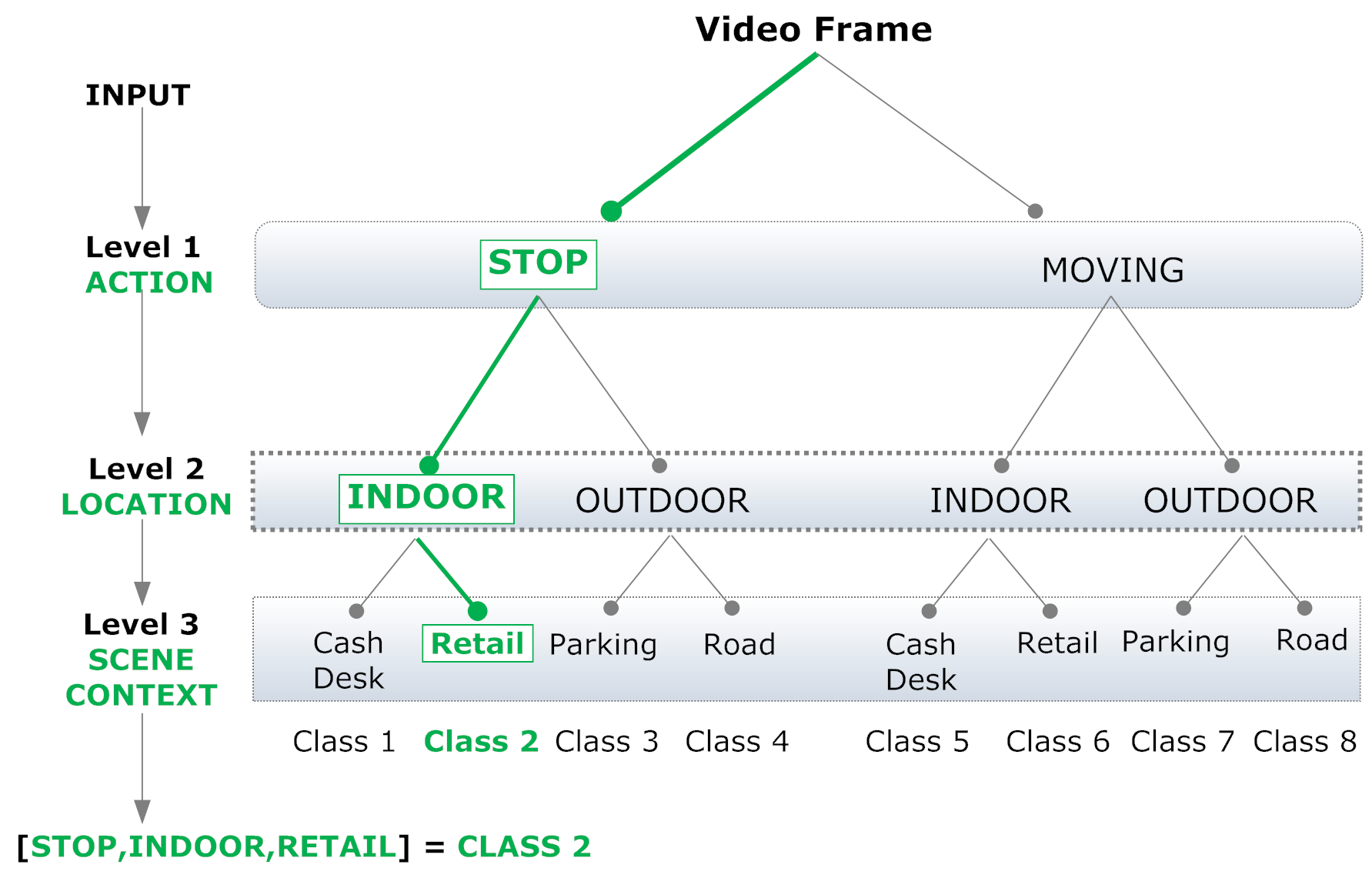 V. Santarcangelo, G. M. Farinella, S. Battiato. Egocentric Vision for Visual Market Basket Analysis.
Web Page
V. Santarcangelo, G. M. Farinella, S. Battiato. Egocentric Vision for Visual Market Basket Analysis.
Web Page
We introduce a new application scenario for egocentric vision: Visual Market Basket Analysis (VMBA). The main goal in the proposed application domain is the understanding of customers behaviors in retails from videos acquired with cameras mounted on shopping carts (which we call narrative carts). To properly study the problem and to set the first VMBA challenge, we introduce the VMBA15 dataset. The dataset is composed by 15 different egocentric videos acquired with narrative carts during users shopping in a retail.
Location-Based Temporal Segmentation of Egocentric Videos
 A. Furnari, S. Battiato, G. M. Farinella, Personal-Location-Based Temporal Segmentation of Egocentric Video for Lifelogging Applications, submitted to Journal of Visual Communication and Image Representation. Web Page
A. Furnari, S. Battiato, G. M. Farinella, Personal-Location-Based Temporal Segmentation of Egocentric Video for Lifelogging Applications, submitted to Journal of Visual Communication and Image Representation. Web Page
We propose a method to segment egocentric videos on the basis of the locations visited by user. To account for negative locations (i.e., locations not specified by the user), we propose an effective negative rejection methods which leverages the continuous nature of egocentric videos and does not require any negative sample at training time.
Recognizing Personal Locations from Egocentric Videos
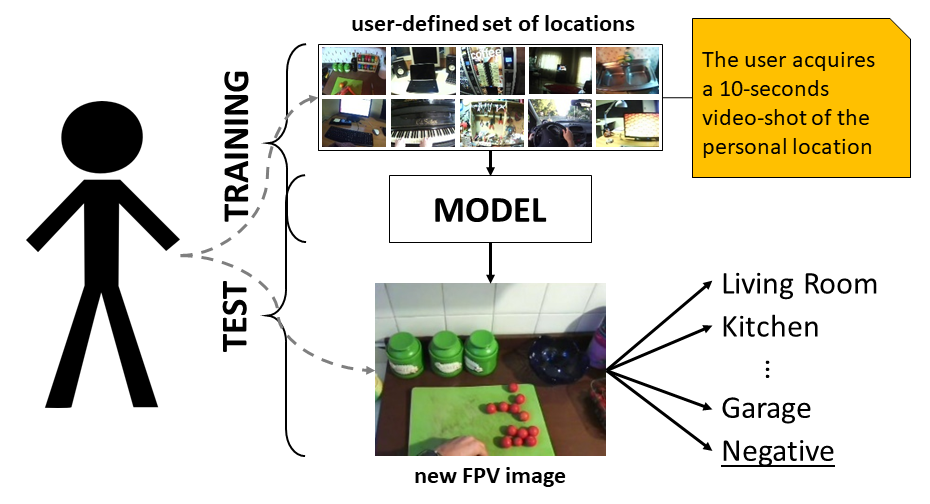 A. Furnari, G. M. Farinella, S. Battiato, Recognition of Personal Locations from Egocentric Videos, IEEE Transactions on Human-Machine Systems. PDF Web Page
A. Furnari, G. M. Farinella, S. Battiato, Recognition of Personal Locations from Egocentric Videos, IEEE Transactions on Human-Machine Systems. PDF Web Page
We study how personal locations arising from the user’s daily activities can be recognized from egocentric videos. We assume that few training samples are available for learning purposes. Considering the diversity of the devices available on the market, we introduce a benchmark dataset containing egocentric videos of 8 personal locations acquired by a user with 4 different wearable cameras. To make our analysis useful in real-world scenarios, we propose a method to reject negative locations.