Anticipation problem has been studied considering different aspects such as predicting humans' locations, predicting hands and objects trajectories, and forecasting actions and human-object interactions.
In this paper, we studied the short-term object interaction anticipation problem from the egocentric point of view, proposing a new end-to-end architecture named StillFast.
Our approach simultaneously processes a still image and a video detecting and localizing next-active objects, predicting the verb which describes the future interaction and determining when the interaction will start.
Experiments on the large-scale egocentric dataset EGO4D show that our method outperformed state-of-the-art approaches on the considered task.
Our method is ranked first in the public leaderboard of the EGO4D short term object interaction anticipation challenge 2022.
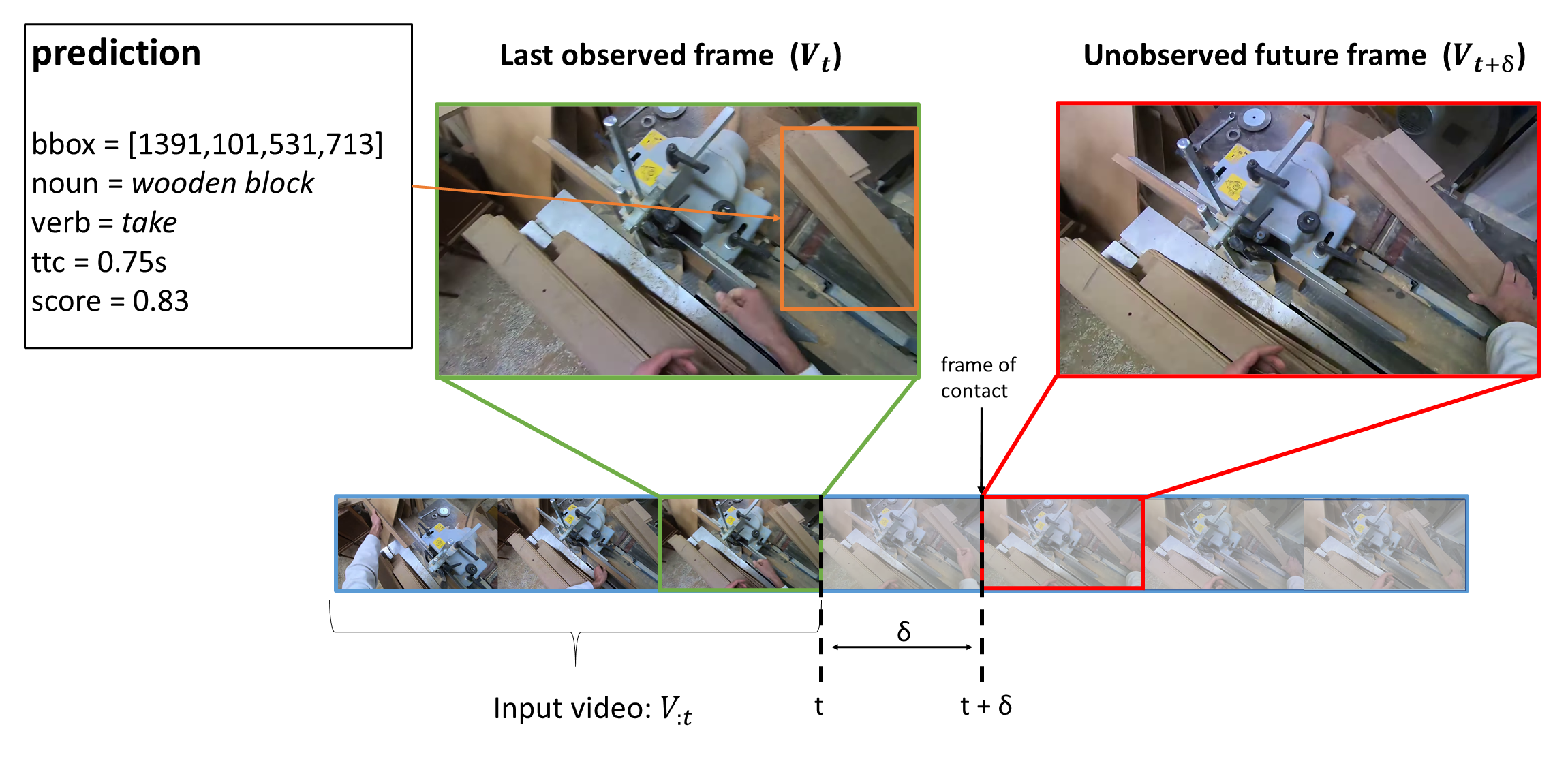
Given a video V and a timestamp t, models can process the video up to time t (denoted as Vt) and are required to output a set of future object interaction predictions which will happen after a time interval δ.
Each prediction consists in: 1) a bounding box localizing the future interacted object (also referred to as next-active object);
2) a noun label describing the class of the detected object (e.g., “wooden block”); 3) a verb label describing the interaction which will take place in the future (e.g., “take”);
4) a real number indicating the “time to contact”, i.e., the time in seconds between the current timestamp and the beginning of the interaction (e.g., 0.75s);
5) a confidence score used to rank future predictions for evaluation.
Method
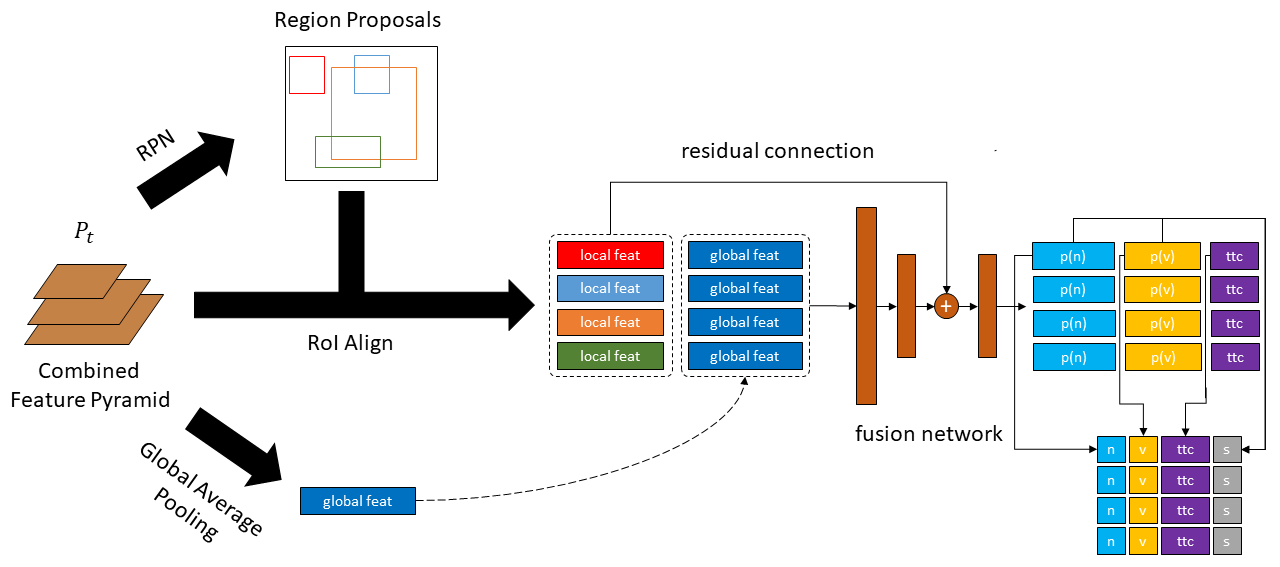
StillFast is composed of a two-branch backbone. A 2D Backbone (“still” branch) processes the high
resolution frame Vt, producing a stack of 2D features Φ2D(Vt).
A 3D Backbone (“fast” branch), processes a low resolution video V(t-τo):t
obtaining a stack of 3D features Φ3D(V(t−τo ):t). The Combined Feature Pyramid Layer is responsible to: 1) up-sample the stack of 3D
features with nearest neighbor interpolation to match the spatial resolution of the 2D features and averages over the temporal dimension
obtaining the Φ 2D/3D (V(t−τo ):t) features which have the same dimension of 2D features Φ2D(Vt), 2) fuse these stack of features obtaining the
final combined feature pyramid Pt.
StillFast Prediction Head is based on the Faster R-CNN prediction head. From the Combined Feature Pyramid Pt we obtain global and local features.
Local features are obtained through a Region Proposal Network (RPN) which predicts region proposals, from which we compute local features through a RoI Align layer.
Global features are obtained with a Global Average Pooling operation and are concatenated with local features. These features are fed in a fusion network and then are summed to the original local features through residual connections.
These local-global representations are finally used to predict object (noun) and verb probability distributions and time-to-contact (ttc) through linear layers along with the related prediction score s.
F. Ragusa, G. M. Farinella, A. Furnari. StillFast: An End-to-End Approach for Short-Term Object Interaction Anticipation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2023.
@InProceedings{ragusa2023stillfast,
author={Francesco Ragusa and Giovanni Maria Farinella and Antonino Furnari},
title={StillFast: An End-to-End Approach for Short-Term Object Interaction Anticipation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
year = {2023}
}
Acknowledgement
This research is supported by Next Vision s.r.l., by the project Future Artificial Intelligence Research (FAIR) – PNRR MUR Cod. PE0000013 - CUP: E63C22001940006 and by the project MISE - PON I&C 2014-2020 - Progetto ENIGMA - Prog n. F/190050/02/X44 – CUP: B61B19000520008.