

|
Download Paper |

Since their first creation, Deepfakes have been widely used for malicious purposes such as in the pornography industry. Therefore, the need to counteract the illicit use of this powerful technology was born. So much work has been proposed in the literature but unfortunately most of it lacks generalizability. The purposes of this challenge is to create (a) "in the wild" Deepfake detection algorithms that can counteract the malicious use of these powerful technologies and (b) try to reconstruct the source image from those Deepfakes. To this aim, the challenge will be divided into two tasks as described in the following subsections. Given the importance and the dangerousness of Deepfake the entire challenge will focus only on Deepfake images of human faces.
This part of the challenge is the classical Deepfake detection binary classification task.
The participants’ solutions should be able to define whether an image is real or deepfake.
The participants’ solutions will be evaluated with particular emphasis in terms of
“robustness” to common alterations on images such as: rotation, mirroring,
gaussian-filtering, scaling, cropping and re-compressions.
The winning team of Task 1 will receive a prize of 500 €.
This part of the challenge is a task never addressed in literature: given a deepfake
image generated with a specific architecture and model (StarGAN-v2 [8]), the goal
is to best reconstruct the source image in its original form starting from the deepfake counterpart.
The winning team of Task 2 will receive a prize of 500 €.
Additional details of the tasks, datasets, and the challenge rules will be described in Evaluation Criteria, Competitions Rules and Dataset Sections.
The proposed challenge aims to ask the participants to produce new techniques to fight
against deepfake images.
For this purpose the challenge will be divided into two tasks with
different objectives and submissions evaluation metrics.
The two tasks will be described in
terms of data provided and evaluation metrics as the following.

The dataset provided will be composed of both real and Deepfake images of human faces.
The Deepfake images will be generated by means of several GAN architectures based on
well-known deepfake manipulations such as: face transfer, face swap and style transfer.
The training set will be composed of images and organized into several ZIP files having as structure
"LABEL-GANname.ZIP" (e.g., "0-CELEBA.ZIP", "1-StarGAN.ZIP"), where LABEL is the Ground Truth
(value equal to 0 if the dataset contains real images; value equal to 1 if the dataset contains deepfake
images).
Participants will organize these datasets as they see fit (split them into training and validation,
define the split percentage, etc.) and can perform any augmentation operation as long as they use
only the dataset provided for the competition.
The test set, released in the last part of the competition (see the
Important Dates section),
will be a TEST.ZIP file composed by several real and Deepfake images similar to those of the training set, and
in addition,
images obtained by applying some processing (rotation, mirroring, gaussian-filtering,
scaling, cropping and re-compression) will be introduced.
For this task, the winning team will be selected with respect to the highest classification accuracy value
obtained on the
Real vs. Deepfake binary classification task computed with participants’ solutions on a
further set of data not available until the end of the challenge submission period.
NOTE THAT: only the solutions that will be submitted not later than the defined deadline
will be considered. All solutions submitted after the deadline will not be considered.
Figure 1 summarizes the objective of Task 1.
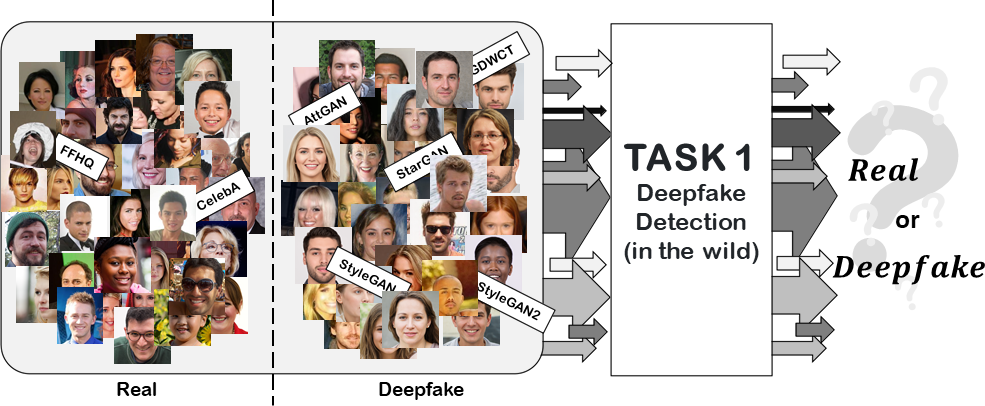
Figure 1: Deepfake Detection task.
The dataset provided will consist of images manipulated by the Stargan-v2 [8]
architecture. In detail, each Deepfake sample is obtained through the attribute manipulation operation performed
via the StarGAN v2 architecture on a source image (src) with respect to the attributes of a reference image (ref).
Figure 2 shows an example.
The dataset is organized into 3 different ZIP files: SOURCES.ZIP, REFERENCES.ZIP
and Deepfake.ZIP. Each Deepfake sample, available in Deepfake.ZIP, has a filename that follows the following structure:
deepfake-src_IDs-ref_IDr.JPG, where
IDs refers to the ID of the source image that can be found in the SOURCES.ZIP
(with filename src_IDs.JPG) and, IDr refers to
the ID of the reference image that can be found in the REFERENCES.ZIP
with filename ref_IDr.JPG). See Figure 2.
Participants will organize these datasets as they see fit (split them into training and validation,
define the split percentage, etc.) and can perform any augmentation operation as long as they only use
the dataset provided for the competition.
The test set, released in the last part of the competition (see the Important
Dates section), will consist ONLY of Deepfake images.
Participants must share only the reconstructed images.
For this competition, the winning team will be selected based on the "minimum average
distance to Manhattan" calculated (by the organizers)
between the sources (available only to the organizers and made public once the competition is over)
and the images reconstructed by the participants.
NOTE THAT: only the solutions that will be submitted not later than the defined deadline
will be considered. All solutions submitted after the deadline will not be considered.
Figure 3 summarizes the objective of Task 2.
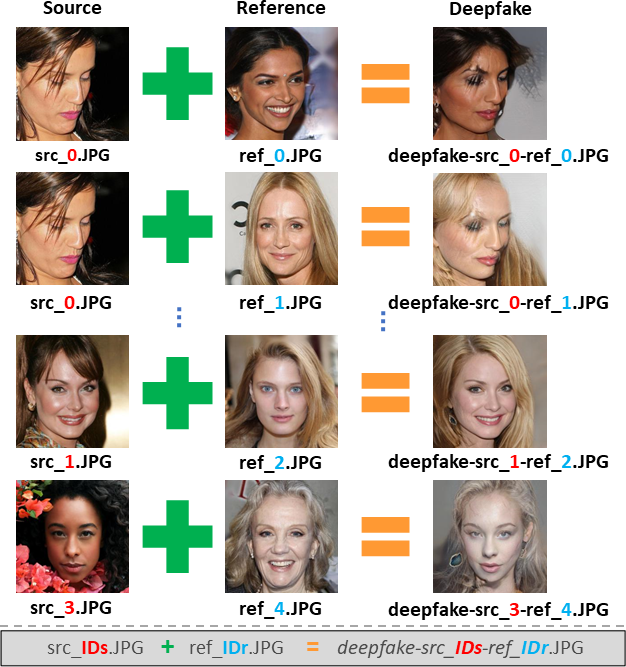
Figure 2: Name structure of source images, reference images and deepfake images.
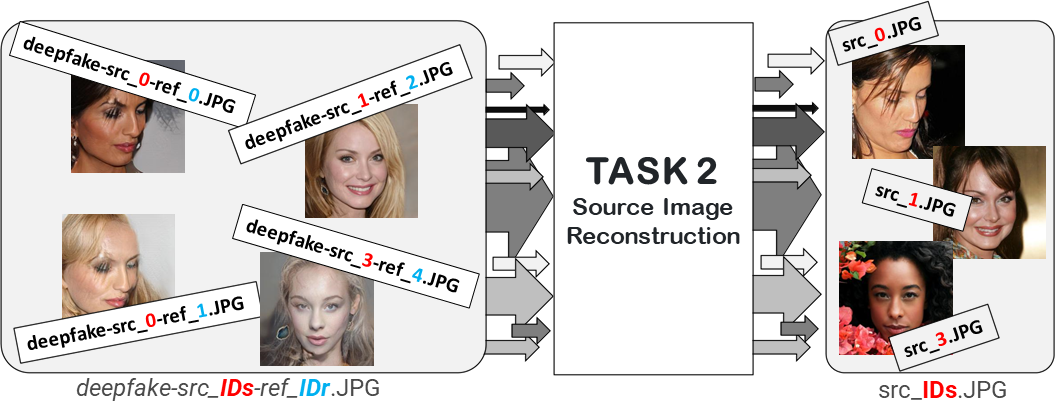
Figure 3: Source image reconstruction task.
Participants should start preparing a descriptive documentation for their final submission.
Indeed, top-ranked teams will be invited to present their works at the ICIAP 2021
conference during the competition session. More details will be available in this web
site.
Each team is invited to participate freely in one of
the two tasks or in all the tasks listed above.
No later than 15/01/2022 participants must register at this following website
where they must specify the team name, affiliation, and other informations.
It will not be allowed to unify teams after the beginning of the challenge even if they
belong to the same university.
The technical documentation that participants must
submit no later than 28/02/2022 must be written in English and must contain all
the details of the proposed approach (for example, if you use a deep neural network
algorithm then you must describe the architecture used, the parameters, etc.) and the
results obtained, as well as the comparison with the methods reported at the Related Research section
and other recent state-of-the-art
methods that are deemed necessary, inherent, and important to participants.
For the first task, by using the TEST set released on the date indicated in Important
Dates section, participants will need to create and submit a simple .TXT file specifying for each row the
name of the analyzed image and the estimated label:
--- file.txt
------ name_image_1.jpg 0/1 \n
------ name_image_2.jpg 0/1 \n
...........................................................
------ name_image_N.jpg 0/1
Example:
--- team0.txt
------ 000.jpg 1 \n
------ 001.jpg 1 \n
------ 002.jpg 0 \n
...........................................................
------ N.jpg 0
The winner will be determined based on the highest classification accuracy
value obtained in this last phase.
NOTE THAT participants must upload on THIS WEBSITE
(after having carried out
the login procedure) and
ONLY for TASK 1 the TXT file described above and the related documentation (PDF) written
in English language. The data upload phase on this platform will be made available on the
dates reported in the Important Dates section. Participants have only
5 different uploads available: one is used to upload the documentation (.pdf) and four are
available to upload the .TXT of the results. Only the last files (.TXT and documentation) uploaded will be
considered by the organizers. Results without documentation (.pdf) will not be evaluated
by the organizers.
Training is allowed only on the provided datasets. Participants are allowed to fine-tune
pre-trained models among those available at:
For the second task, by using the TEST set released on the date indicated in Important
Dates section, participants must share a Google Drive folder,
with the related documentation
(PDF) and a sub-folder containing ONLY the
reconstructed images (with the same name as the respective Deepfake image), to the
following email
address: deepfakechallenge@gmail.com.
The email must have as subject TEAM_NAME - ICIAP2022_Task2
The winner will be determined based on the
lowest mean value of Manhattan distances.
Results without documentation (.pdf) will not be evaluated
by the organizers.
Training is allowed only on the provided datasets. Participants are allowed to
fine-tune pre-trained model among those available at:
Two datasets of real face images were used for the employed experimental phase: CelebA and FFHQ. Different Deepfake images were generated considering StarGAN, GDWCT, AttGAN, StyleGAN and StyleGAN2 architectures. In particular, CelebA images were manipulated using pre-trained models available on Github, taking into account StarGAN, GDWCT and AttGAN. Images of StyleGAN and StyleGAN2 created through FFHQ were downloaded as detailed in the following:
The winning team of Task 1 will receive a prize of 500 €.
The winning team of Task 2 will receive a prize of 500 €.








