


Fighting Deepfake by Exposing the Convolutional Traces on Images
IEEE Access 2020
Luca Guarnera1,2, Oliver Giudice1, Sebastiano Battiato1,2
1 Department of Mathematics and Computer Science, University of Catania, Italy
2 iCTLab s.r.l. Spinoff of University of Catania, Italy
luca.guarnera@unict.it (luca.guarnera@ictlab.srl), {giudice, battiato}@dmi.unict.it

Examples of Deepfakes: (a) Jim Carrey's face transferred to Alison Brie's body,
(b) Mr. Bean is Charlize Theron in a Deepfake version of J'adore commercial,
(c) Jim Carrey instead of Jack Nicholson in Shining and
(d) Tom Cruise Replaces Robert Downey Jr. in Iron Man.
ABSTRACT
Advances in Artificial Intelligence and Image Processing are changing the way people interacts with digital images and video. Widespread mobile apps like FACEAPP make use of the most advanced Generative Adversarial Networks (GAN) to produce extreme transformations on human face photos such gender swap, aging, etc. The results are utterly realistic and extremely easy to be exploited even for non-experienced users. This kind of media object took the name of Deepfake and raised a new challenge in the multimedia forensics field: the Deepfake detection challenge. Indeed, discriminating a Deepfake from a real image could be a difficult task even for human eyes but recent works are trying to apply the same technology used for generating images for discriminating them with preliminary good results but with many limitations: employed Convolutional Neural Networks are not so robust, demonstrate to be specific to the context and tend to extract semantics from images. In this paper, a new approach aimed to extract a Deepfake fingerprint from images is proposed. The method is based on the Expectation-Maximization algorithm trained to detect and extract a fingerprint that represents the Convolutional Traces (CT) left by GANs during image generation. The CT demonstrates to have high discriminative power achieving better results than state-of-the-art in the Deepfake detection task also proving to be robust to different attacks. Achieving an overall classification accuracy of over 98%, considering Deepfakes from 10 different GAN architectures not only involved in images of faces, the CT demonstrates to be reliable and without any dependence on image semantic. Finally, tests carried out on Deepfakes generated by FACEAPP achieving 93% of accuracy in the fake detection task, demonstrated the effectiveness of the proposed technique on a real-case scenario.

|
Download Paper |

Dataset
Experiments were carried out considering images created by STARGAN, ATTGAN, GDWCT, STYLEGAN, STYLEGAN2 and FACEFORENSICS++ for Deepfake of faces in conjunction with other four Deepfake architectures not dealing with faces: CYCLEGAN, PROGAN, IMLE and SPADE. Figure shows a brief presentation of the employed images, the techniques, targets, semantics, etc. by reporting also details about training and testing purposes.
Download:
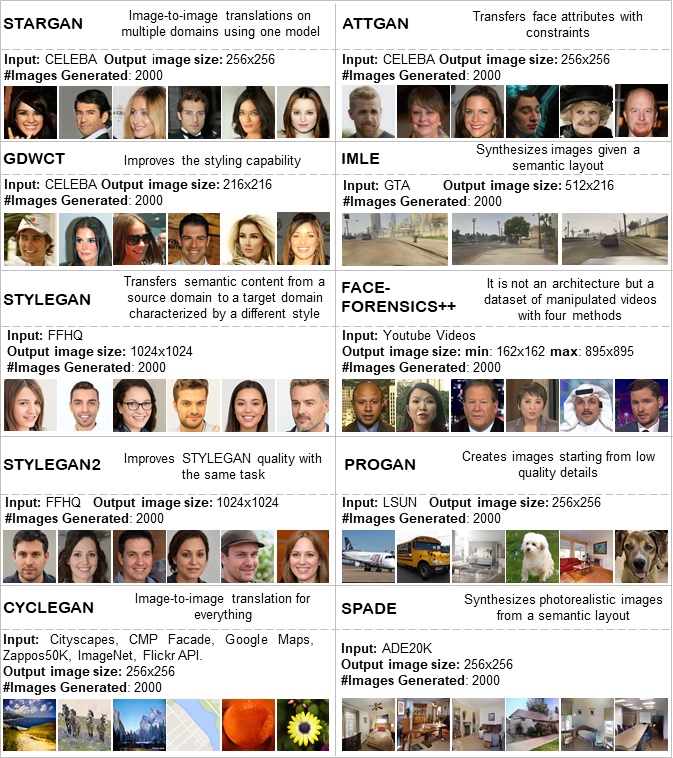
Details for each image set used in this paper. On the right of each deep architecture's name is reported a brief description. Input represents the dataset used for both training and test phase of the respective architecture. Image size describes the image size of the generated Deepfakes dataset. As regards FACEFORENSICS++ is concerned that for each video frame, the patch referring to the face, is detected and extracted automatically. This patch could have different sizes. #Images Generated describes the total number of images taken into account for the considered architecture. Finally, image examples are reported.