


Fighting deepfakes by detecting GAN DCT anomalies
Journal of Imaging 2021
(This article belongs to the Special Issue Image and Video Forensics)
Oliver Giudice1, Luca Guarnera1,2, Sebastiano Battiato1,2
1 Department of Mathematics and Computer Science, University of Catania, Italy
2 iCTLab s.r.l. Spinoff of University of Catania, Italy
luca.guarnera@unict.it (luca.guarnera@ictlab.srl), {giudice, battiato}@dmi.unict.it
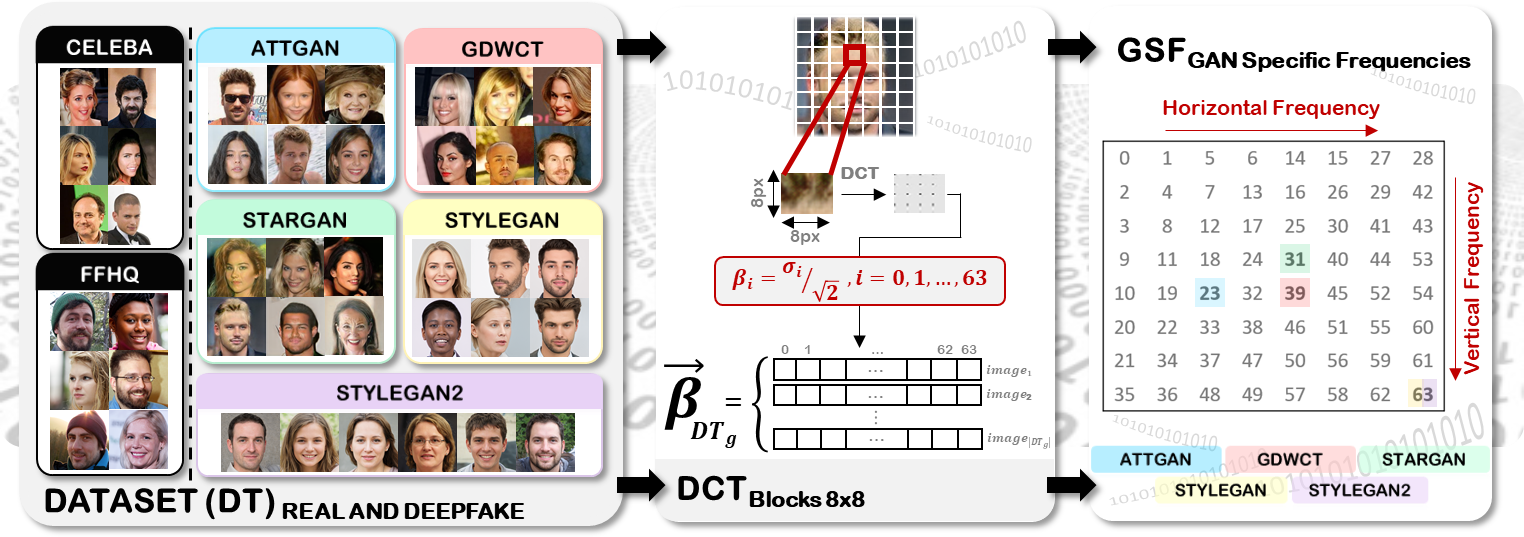
GSF approach: (a) Dataset used for the experiments;
(b) Estimation of β feature vectors after DCT transform applied to
each 8x8 block of all datasets; (c) GSF that identify the generative architectures.
ABSTRACT
Synthetic multimedia contents created through AI technologies, such as Generative Adversarial Networks (GAN), applied to human faces can have serious social and political consequences. State-of-the-art algorithms employ deep neural networks to detect fake contents but, unfortunately, almost all approaches appear to be neither generalizable nor explainable. In this paper, a new fast detection method able to discriminate Deepfake images with high precision is proposed. By employing Discrete Cosine Transform (DCT), anomalous frequencies in real and Deepfake image datasets were analyzed. The β statistics inferred by the distribution of AC coefficients have been the key to recognize GAN-engine generated images. The proposed technique has been validated on pristine high quality images of faces synthesized by different GAN architectures. Experiments carried out show that the method is innovative, exceeds the state-of-the-art and also gives many insights in terms of explainability.

|
Download Paper |

Datasets Details
Two datasets of real face images were used for the employed experimental phase: CelebA and FFHQ. Different Deepfake images were generated considering StarGAN, GDWCT, AttGAN, StyleGAN and StyleGAN2 architectures. In particular, CelebA images were manipulated using pre-trained models available on Github, taking into account StarGAN, GDWCT and AttGAN. Images of StyleGAN and StyleGAN2 created through FFHQ were downloaded as detaled in the following:
- CelebA (CelebFaces Attributes Dataset): a large-scale face attributes dataset with more than 200K celebrity images, containing 40 labels related to facial attributes such as hair color, gender and age. The images in this dataset cover large pose variations and background clutter. The dataset is composed by 178x218 JPEG images.
- FFHQ (Flickr-Faces-HQ): is a high-quality image dataset of human faces with variations in terms of age, ethnicity and image background. The images were crawled from Flickr and automatically aligned and cropped using dlib [1]. The dataset is composed by high-quality 1024x1024 PNG images.
- StarGAN: is able to perform Image-to-image translations on multiple domains using a single model. Using CelebA as real images dataset, every image was manipulated by means of a pre-trained model (https://github.com/yunjey/stargan) obtaining a final resolution equal to 256x256 (PNG format).
- GDWCT: is able to improve the styling capability. Using CelebA as real images dataset, every image was manipulated by means of a pre-trained model (https://github.com/WonwoongCho/GDWCT) obtaining a final resolution equal to 216x216 (PNG format).
- AttGAN: is able to transfers facial attributes with constraints. Using CelebA as real images dataset, every image was manipulated by means of a pre-trained model (https://github.com/LynnHo/AttGAN-Tensorflow) obtaining a final resolution equal to 256x256 (PNG format).
- StyleGAN: is able to transfers semantic content from a source domain to a target domain characterized by a different style. Images have been generated (JPEG format) considering FFHQ as dataset in input with 1024x1024 resolution (https://drive.google.com/drive/folders/1uka3a1noXHAydRPRbknqwKVGODvnmUBX).
- StyleGAN2: improves STYLEGAN quality with the same task. Images have been generated (PNG format) considering FFHQ as dataset in input with 1024x1024 resolution (https://drive.google.com/drive/folders/1QHc-yF5C3DChRwSdZKcx1w6K8JvSxQi7).

Figure 1: Examples of Real images (a) and Deepfake images (b)
Finalizing the GSF approach
Instead of using only the corresponding β to the GSF, it will employ a feature vector with all 63 β, consequently used as input to a Gradient Boosting classifier and tested in a noisy context that includes a number of plausible attacks on the images under analysis. Gradient Boosting was selected as the best classifier for data and the following hyper-parameters were selected by means of a 10% of the dataset employed as validation set. We selected the following hyper parameters: number-of-estimators = 100, learning-rate = 0.6, maxdepth = 2. The robust classifier thus created, fairly identify the most probable GAN from which the image has been generated, providing hints for "visual explainability". By considering the growing availability of Deepfakes to attack people reputation such aspects become fundamental to assess and validate forensics evidence. In particular the "robust classifier" was trained by employing only 10% of the entire dataset for training, 10% for validation while the remaining part was used as test set. The dataset was augmented with many types of attacks (Section: Testing with Noise). Cross-validation was carried out.Testing with Noise
All the images collected in the corresponding Datasets have been put through different kinds of attacks as addition of a random size rectangle, position and color, Gaussian blur, rotation and mirroring, scaling and various JPEG Quality Factor compression (QF), in order to demonstrate the robustness of the GSF approach.As shown in Table 1 this type of attacks do not destroy the GSF obtaining high accuracy values.
- Gaussian Blur applied with different kernel sizes (3x3, 9x9, 15x15) could destroy different main frequencies in the images. This filtering preserves low frequencies by almost totally deleting the high frequencies, as the kernel size increases. It is possible to see in Table 1, that the accuracy decreases at increasing of the kernel size. This phenomenon, is particularly visible for images generated by AttGAN, GDWCT and StarGAN which have the lowest resolution.
- Several degrees of rotation (45, 90, 135, 180, 255) were considered since they can modify the frequency components of the images. Rotations with angles of 90, 180, and 270 do not alter the frequencies because the [x,y] pixels are simply moved to the new [x',y'] coordinates without performing any interpolation function, obtaining high values of detection accuracy. On the other hand, when considering different degrees of rotation, it is necessary to interpolate the neighboring pixels to get the missing ones. In this latter case, new information is added to the image that can affect the frequency information. In fact, considering rotations of 45, 135, 225 degree, the classification accuracy values decrease; except for the two StyleGANs for the same reason described for the Gaussian filter (i.e. high resolution).
- The mirror attack reflects the image pixels along one axis (horizontal, vertical and both). This does not alter image frequencies, obtaining extremely high accuracy detection values.
- The resizing attacks equal to -50% of resolution causes a loss of information, hence, already small images tend to totally lose high-frequency components presenting a behavior similar to low-pass filtering; in this case accuracy values are inclined to be low. Viceversa, a resizing of +50% doesn't destroy the main frequencies obtaining a high classification accuracy values.
- Finally, different JPEG compression quality factors were applied (QF = 1, 50, 100). As expected in Table 1, a compression with QF = 100 does not affect the results. The overall accuracy begins to be affected as the QF decreases, among other things, destroying the DCT coefficients. However, at QF = 50 the mid-level frequencies are still preserved and the results maintain a high level of accuracy. This is extremely important given that this level of QF is employed by the most common social platforms such as Whatsapp or Facebook, thus demonstrating that the GSF approach is extremely efficient in real-world scenarios.

Figure 2: Examples of Deepfake images after attacks.
Comparison and Generalization Tests
The GSF approach is extremely simple, fast, and demonstrates a high level of accuracy even in real-world scenarios. In order to better understand the effectiveness of the technique, a comparison with state-of-the-art methods was performed and reported in this section. The trained robust classifier was compared to the most recent work in the literature and in particular Zhang et al.[2] (AutoGAN), Wang et al.[3] (FakeSpotter) and Guarnera et al.[4] (Expectation-Maximization) were considered for the use of a few GAN architectures in common with the analysis performed in this paper: StyleGAN, StyleGAN2, StarGAN. Table 2 shows that the GSF approach achieves the best results with an unbeatable accuracy of 99.9%.Another comparison was made on the detection of StyleGAN and StarGAN with respect to [4,5]. The obtained results are shown in the Table 3 in which the average precison values of each classification task are reported.
A specific discussion is needed for testing the FaceForensics++ (FF++) dataset [6] which is a challenging dataset of fake videos of people speaking and acting in several contexts.
By means of OpenCV's face detectors, cropped images of faces were taken from Deepfake videos of FF++ (at different compression levels) and a dataset of 3000 images with different resolutions (minresolution = 162 x 162 px, maxresolution = 895 x 895 px) was obtained. The GSF approach was employed to construct the β feature vector computed on the DCT coefficients and the robust classifier was used for binary classification in order to perform this "in the wild" test.
We emphasize that the latter datasets (FF++) were only used in the testing phase with the robustness classifier. Since the classifier detected FaceForensics++ images as well as StyleGAN images, we also tried to calculate the GSF by comparing FaceForensics++ images with FFHQ obtaining a value of 61 which is extremely close to the GSF of StyleGANs. The results obtained on FaceForensics++ are reported in Table 3 showing how the GSF approach is an extremely simple and fast method capable of beating the state-of-the-art even on datasets on which it has not been trained.
References
[1] Davis E. King. Dlib-ml: A machine learning toolkit.Journalof Machine Learning Research, 10:1755-1758, 2009.[2] X. Zhang, S. Karaman, and S.-F. Chang, "Detecting and simulating artifacts in gan fake images," in 2019 IEEE International Workshop on Information Forensics and Security (WIFS).IEEE, 2019, pp. 1-6.
[3] R. Wang, L. Ma, F. Juefei-Xu, X. Xie, J. Wang, and Y. Liu, "Fakespotter: A simple baseline for spotting AI-synthesized fake faces," arXiv preprint arXiv:1909.06122, 2019.
[4] L. Guarnera, O. Giudice, and S. Battiato, "Fighting deepfake by exposing the convolutional traces on images," IEEE Access, vol. 8, pp. 165 085-165 098, 2020.
[5] S.-Y. Wang, O. Wang, R. Zhang, A. Owens, and A. A. Efros, "Cnn-generated images are surprisingly easy to spot... for now," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 7, 2020.
[6] A. Rossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Niessner, "Faceforensics++: Learning to detect manipulated facial images," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 1-11.
[7] J. Thies, M. Zollhofer, M. Stamminger, C. Theobalt, and M. Niessner, "Face2face: Real-time face capture and reenactment of rgb videos," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2387-2395.