We present the first step towards the construction of a wearable system capable of assisting the visitors of cultural sites. In particular, in this work we concentrate on the room-based localization of visitors from egocentric visual signals. The contribution of this work is two-fold:
a new large dataset of egocentric videos acquired in a real cultural site by multiple subjects with two different devices: a Microsoft HoloLens and a chest-mounted GoPro;
a benckmark study of different baseline approaches for room-based localization task considering the proposed dataset.
Results and Demo
A video example of our system in action is shown below. Other videos demonstrating the results are at the following page . Quantitative results are summarized in the following tables (see the paper for more details).
At the following link is avalaible a demo of our Manager Visualization Tool (MVT). The tool allows the manager to analyze the output of the system which automatically localizes the visitor in each frame of the video.
Hololens
AVG Discrimination
AVG Rejection
AVG Sequential Modeling
Class
FF1
ASF1
FF1
ASF1
FF1
ASF1
1 Cortile
0,50
0,012
0,45
0,015
0,60
0,476
2 Scalone Monumentale
0,81
0,005
0,84
0,008
0,96
0,898
3 Corridoi
0,77
0,002
0,69
0,003
0,92
0,794
4 Coro Di Notte
0,71
0,001
0,67
0,005
0,91
0,663
5 Antirefettorio
0,66
0,003
0,73
0,007
0,95
0,830
6 Aula Santo Mazzarino
0,69
0,002
0,65
0,003
0,99
0,960
7 Cucina
0,72
0,001
0,60
0,002
0,70
0,525
8 Ventre
0,97
0,003
0,94
0,003
0,96
0,920
9 Giardino dei Novizi
0,79
0,007
0,79
0,009
0,83
0,780
Neg
/
/
0,24
0,005
0,42
0,270
AVG
0,73
0,004
0,66
0,006
0,82
0,712
GoPro
AVG Discrimination
AVG Rejection
AVG Sequential Modeling
Class
FF1
ASF1
FF1
ASF1
FF1
ASF1
1 Cortile
0,84
0,152
0,25
0,025
0,57
0,675
2 Scalone Monumentale
0,93
0,050
0,91
0,033
0,95
0,850
3 Corridoi
0,92
0,015
0,83
0,010
0,97
0,882
4 Coro Di Notte
0,91
0,009
0,64
0,005
0,92
0,580
5 Antirefettorio
0,83
0,018
0,62
0,008
0,95
0,878
6 Aula Santo Mazzarino
0,81
0,001
0,23
0,001
0,90
0,810
7 Cucina
0,90
0,010
0,11
0,002
0,86
0,735
8 Ventre
0,99
0,317
0,86
0,033
0,88
0,657
9 Giardino dei Novizi
0,82
0,152
0,78
0,040
0,82
0,830
Neg
/
/
0,18
0,004
0,30
0,230
AVG
0,88
0,080
0,54
0,016
0,81
0,713
Dataset
We collected a large dataset comprising videos acquired at the Monastero dei Benedettini which is located in Catania, Italy. The dataset has been acquired using two wearable devices: Microsoft Hololens and a chest mounted GoPro Hero4. The two devices have been used simultaneously to acquire the whole dataset. This way, we obtain two separate and compliant datasets: one containing only data acquired using the HoloLens device and the other one containing only data acquired using the GoPro device.
Camera
Resolution
Frame Rate
Microsoft Hololens
1216x684
24 fps
GoPro Hero 4
1280x720
25 fps
We considered a total of 9 environments and 57 points of interests.
For more details about our dataset go to this page .
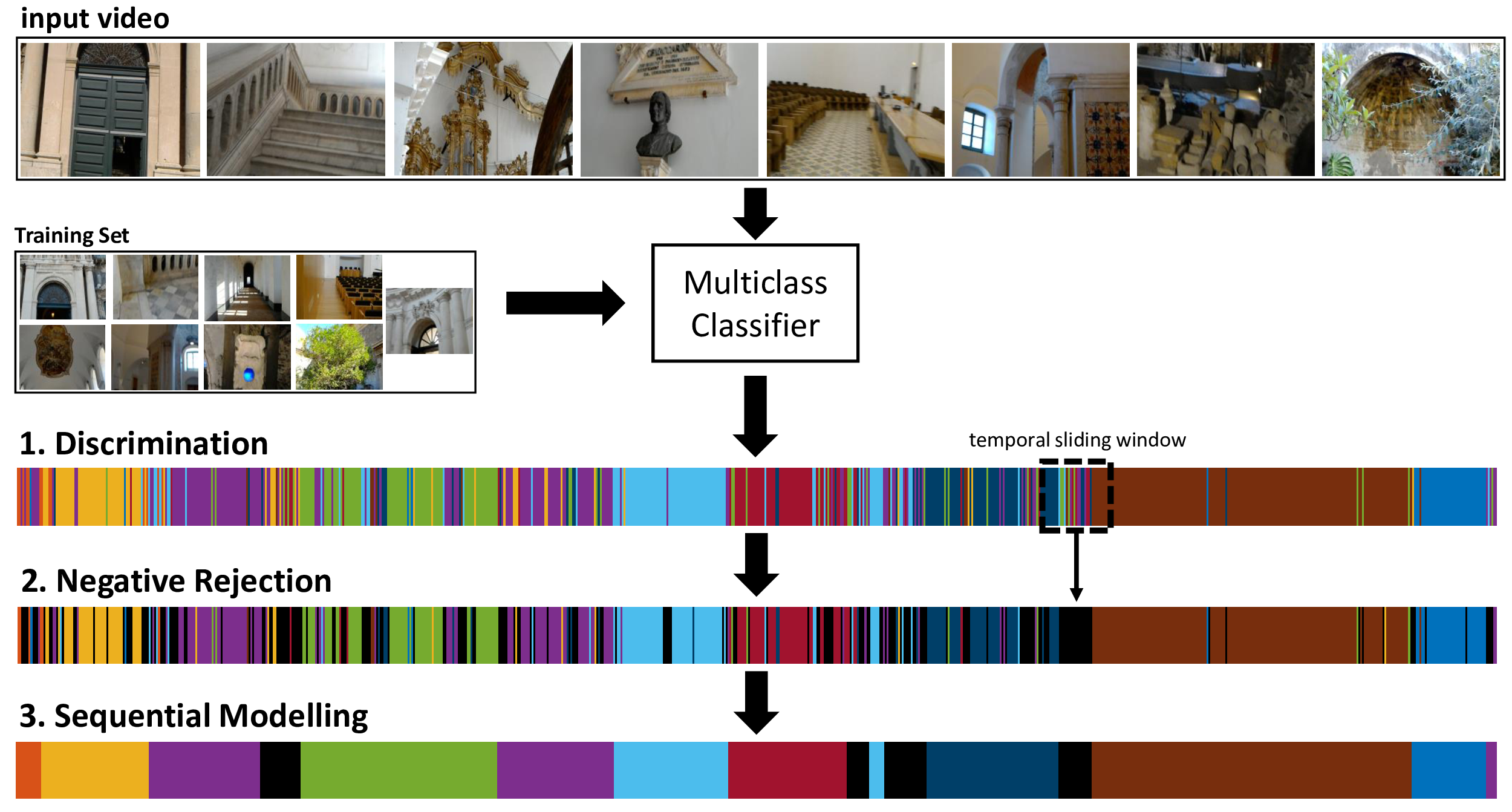
To address the localization task, we follow the approach proposed by Furnari et al.[1]. At training time, the model relies on a labelled set of images (e.g., the frames of a video) acquired in the different environments of interest. Since it is not easy to predict which ``negative'' environments a user will visit at test time, the training set only needs to contain ``positive'' samples, i.e., samples belonging to the considered environments of interests.
At test time, an input egocentric video is processed in three steps. The first step is termed Discrimination and consists in assigning each frame to one of the considered ``positive'' environments. At this stage, no negatives are taken into account.
The second step is termed Negative Rejection and consists in determining which parts of the video are likely to contain frames not belonging to any of the considered ``positive'' environments. Since negative samples were not present at training time, the CNN model is likely to predict noisy labels for each of the frames of the segment. Hence, do detect such segments, a sliding window comprising K frames is employed. The likelihood of the central frame of the sliding window to belong to the negative class is hence quantified computing the variation ratio over the distribution of predicted labels within the window. Such estimated likelihood is hence used to form a frame-wise posterior distribution over both the positive and the negative class.
The output of the first two stages is likely to be a noisy collection of frame-wise prediction. In order to leverage the assumption that egocentric videos are acquired continuously, a third step termed Sequential Modelling is introduced. In this step, a Hidden Markov Model (HMM) is introduced to smooth predictions over time.
Once each frame has been assigned a label, a structured representation of the segments is obtained by considering the connected components of the labels.
Code
We provide two CNN models and Python code related to this paper:
The CNN model trained only on Hololens data [the list of frames used for Training and Validation is included] ( Download);
The CNN model trained only on GoPro data [the list of frames used for Training and Validation is included] ( Download);
The Discrimination method using a CNN model ( Download);
F. Ragusa, A. Furnari, S. Battiato, G. Signorello, G. M. Farinella. Egocentric Visitors Localization in Cultural Sites. In Journal on Computing and Cultural Heritage (JOCCH), 2019. Download the paper here.
Supplementary Material
More details on the dataset can be found in the supplementary material associated to the publication.
Acknowledgement
This research is supported by PON MISE – Horizon 2020, Project VEDI - Vision Exploitation for Data Interpretation, Prog. n. F/050457/02/X32 - CUP: B68I17000800008 - COR: 128032, and Piano della Ricerca 2016-2018 linea di Intervento 2 of DMI of the University of Catania. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.
Related Work
This work is related to the following publication:
G. M. Farinella, G. Signorello, A. Furnari, S. Battiato, E. Scuderi, A. Lopes, L. Santo, M. Samarotto, G. P. A. Distefano, D. G. Marano, “Integrated Method With Wearable Kit For Behavioural Analysis And Augmented Vision" (Italian Version: "Metodo Integrato con Kit Indossabile per Analisi Comportamentale e Visione Aumentata"), Patent Application number 102018000009545, filling date: 17/10/2018, Università degli Studi di Catania, Xenia Gestione Documentale S.R.L., IMC Service S.R.L.
F. Ragusa, L. Guarnera, A. Furnari, S. Battiato, G. Signorello, G. M. Farinella. Localization of Visitors for Cultural Sites Management. In International Conference on Signal Processing and Multimedia Applications (SIGMAP), Porto, Portugal, July 26-28, 2018.
A. Furnari, S. Battiato, G. M. Farinella, Personal-Location-Based Temporal Segmentation of Egocentric Video for Lifelogging Applications, submitted to Journal of Visual Communication and Image Representation Web Page.
A. Furnari, G. M. Farinella, S. Battiato. 2017. Recognizing Personal Locations From Egocentric Videos. IEEE Transactions on Human-Machine Systems (2017). https://doi.org/10.1109/THMS.2016.2612002 Web Page.
A. Furnari, G. M. Farinella, S. Battiato, Temporal Segmentation of Egocentric Videos to Highlight Personal Contexts of Interest, International workshop on egocentric perception, interaction and computing (EPIC) in conjunction with ECCV 2016.
 . Quantitative results are summarized in the following tables (see the paper for more details).
At the following link
. Quantitative results are summarized in the following tables (see the paper for more details).
At the following link  is avalaible a demo of our Manager Visualization Tool (MVT). The tool allows the manager to analyze the output of the system which automatically localizes the visitor in each frame of the video.
is avalaible a demo of our Manager Visualization Tool (MVT). The tool allows the manager to analyze the output of the system which automatically localizes the visitor in each frame of the video. 


 Web Page
Web Page
