 .
.
Filippo Luigi Maria Milotta1,*,
Antonino Furnari1,*,
Sebastiano Battiato1,
Giovanni Signorello2,
Giovanni Maria Farinella1,2
.
The dataset used in this work has been collected asking 12 volunteers to visit the Botanical Garden of the
University of Catania. The garden has a length of about 170m and a width of about 130m. In accordance with
experts, we defined 9 contexts and 9 subcontexts of interest which are relevant to collect
behavioral information from the visitors of the site.

The volunteers have been instructed to visit all 9 contexts without any specific constraint, allowing them to
spend how much time they wished in each context. We asked each volunteer to explore the natural site wearing
a camera and a smartphone during their visit. The wearable camera has been used to collect egocentric videos
of the visits, while the smartphone has been used to collect GPS locations. GPS data has been later synced
with the collected video frames. As a wearable camera, we have used a Pupil 3D Eye Tracker headset.
Videos have been acquired at a resolution of 1280x720 pixels and a framerate of 60 fps. GPS
locations have been recorded using a Honor 9 smartphone.
Due to the limitations of using GPS devices when the sky is not clear or because of the presence of trees, GPS locations have been acquired at a slower rate as compared to videos. Specifically, a new GPS signal has been recoreded about every 14 seconds, depending on the capability of the device to communicate with the GPS satellites. Leveraging video and GPS timestamps stored during the data acquisition, each frame is associated to the closest GPS measurement in time. This leads to the replication of a given GPS location over time.
 |
 |
Using the described protocol, we collected and labeled almost 6 hours of recording, from which we sampled
a total of 63,581 frames for our experiments. The selected frames have been resized to 128x128
pixels to decrease the computational load. Furthermore, since each frame of the dataset has been
labeled with respect to both contexts and subcontexts, location-based classification can be addressed at
different levels of granularity, by considering 1) only the 9 Contexts (coarse localization), 2) only
the
9 Subcontexts (fine localization), or 3) the 17 Contexts obtained by considering the 9 Contexts
and
substituting context 5 Sicilian garden with its 9 Subcontexts (mixed granularity). For evaluation
purposes, the dataset has been divided into 3 different folds by splitting the set of videos from the 12
volunteers into 3 disjoint groups, each
containing videos from 4 subjects. We divided the set of videos such that the frames of each class are
equally distributed in the different folds. Frame distribution for each fold is shown in the following
figure. Histograms have been normalized: they represent the percentage of frames for
each context/subcontext over the total number, for each reported
distribution. We reported together both Training Set [TR] and Test Set (TE).
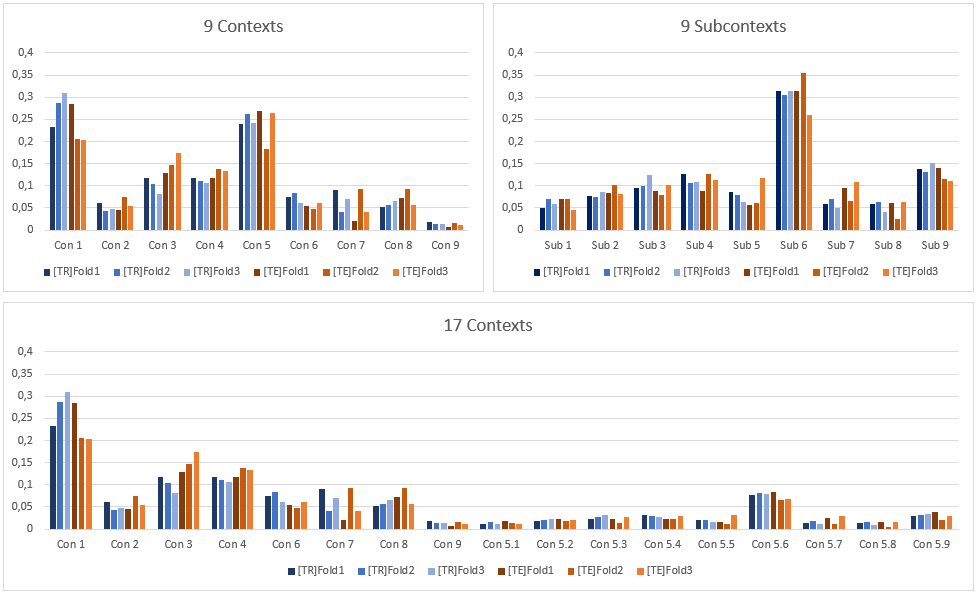
The following table reports information on which videos acquired by the different subjects have been considered in each fold, and the number of frames in each fold.
| Fold | Subjects ID | Frames |
|---|---|---|
| 1 | 2, 3, 7, 8 | 23,145 |
| 2 | 0, 5, 6, 9 | 14,659 |
| 3 | 1, 4, 10, 11 | 25,777 |
You can download the dataset at this link .

