ABSTRACT
Pollen grain classification has a remarkable role in many fields from medicine, to biology and agronomy. Indeed, automatic pollen grain classification is an important task for all related applications and areas. This work presents the first large-scale pollen grain image dataset, including more than 13 thousands objects.
POLLEN GRAIN SEGMENTATION
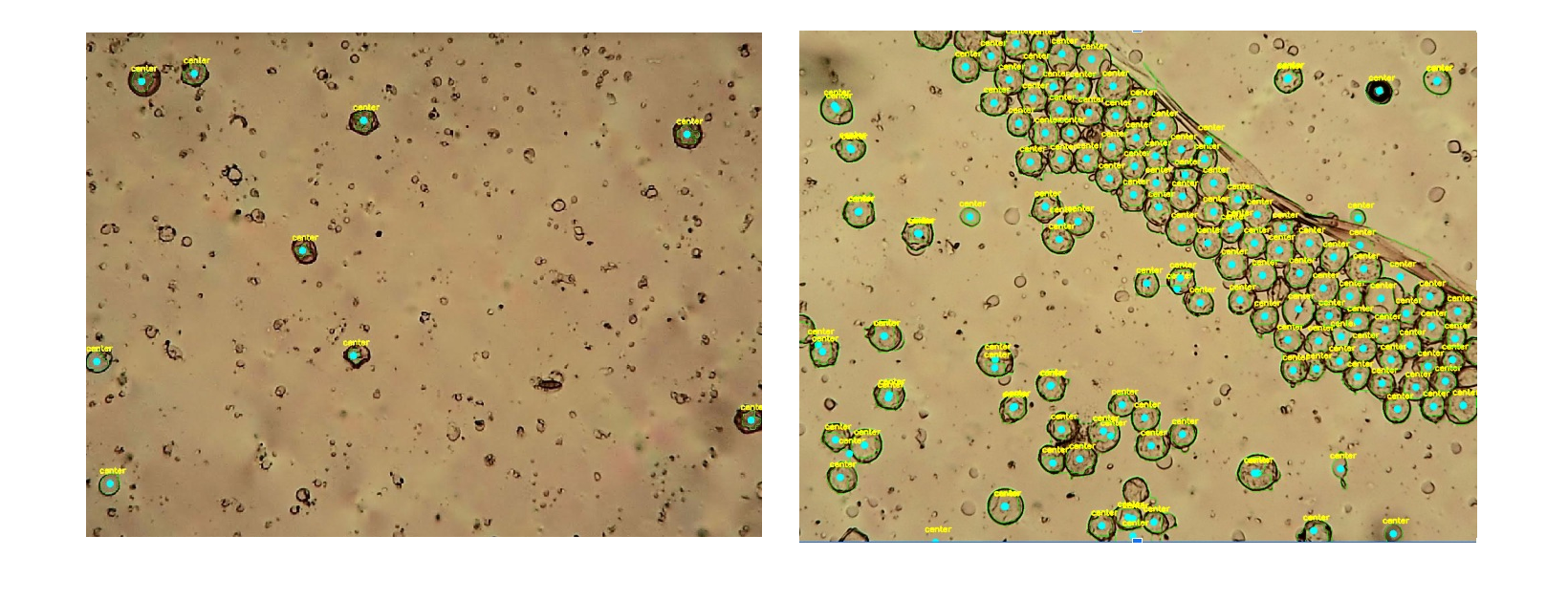
The analysed microscope images present high variability in the number of objects, noise, occlusions color appearance due to chemical reactions and defects of the samples. This made the segmentation of pollen grains a challenging task. The following figures show two different examples. In particular, the second case presents an high number of agglomerated objects, due to a fold on the sample's tape. As shown in the figures, our segmentation pipeline is able to generalize and accomplish the task in both cases.
OBJECT LABELING
Experts in aerobiology field manually labelled segmented objects grouping them into five different categories. The following figure shows the web-baed tool used to label the images.

CLASSIFICATION RESULTS
Experiments with LBP features
Table 1 reports the experiments concerning the LBP feature representation for the input pollen images, considering the evaluated parameters for each employed classification algorithm. Results show that MLP lead to the best results in terms of accuracy (0.8002) and F1 score (0.7764) with an alpha value equal to 0.0001 and a number of estimators equal to 500. We also observed that Linear SVM, Random Forest and AdaBoost performed accurate results yielding an accuracy and F1 score of over greater than 0.70, whereas SVM with RBF kernel showed worst performance. In fact, the classifier achieved an accuracy of 0.3936 and a F1 score of 0.4375 considering a gamma value of 0.001 and a C value of 100.

Experiments with HOG features
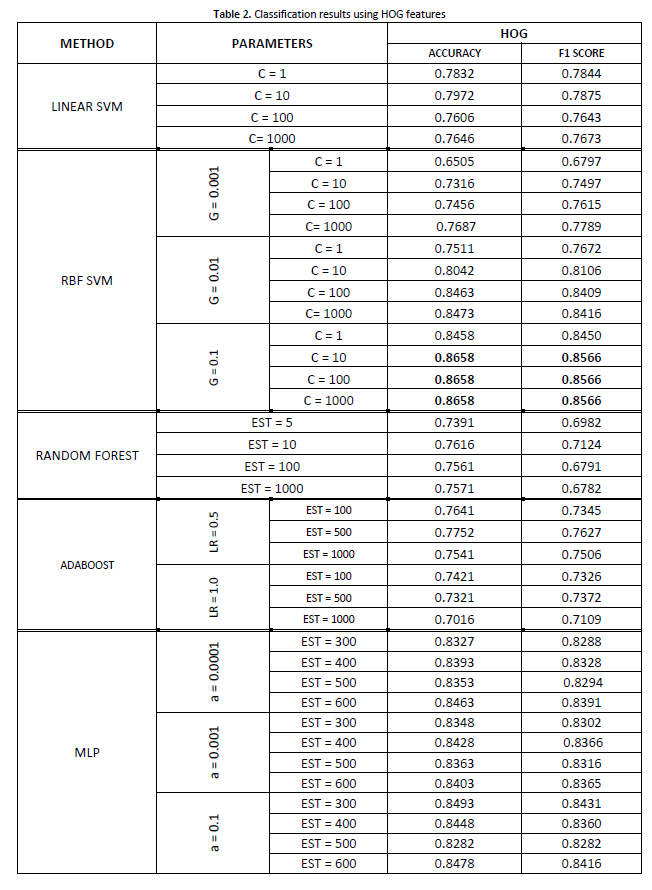
Table 2 reports the experimental results obtained using the HOG features. In this instance, SVM with RBF kernel achieved the highest value in terms of accuracy (0.8658) and F1 score (0.8566), considering a gamma value of 0.1 and a C value of 1000. This specific setting outperforms also the performances of the approaches that take the LBP representation as input reported in Table 1. In particular, all the evaluated approaches detailed in Table 2 achieved accuracy and F1 scores higher than 0.70.
Experiments with Convolutional Neural Networks
Considering that CNNs and Deep Learning models take advantage from huge amount of data, we trained two CNN standard architectures (Alexnet and SmallerVGGNET) considering two different settings for the training data. First, we trained the CNNs considering the standard dataset, composed by the patches depicting the pollen objects. In a second stage, we augmented the dataset by including the segmented version of the training patches obtained by applying the segmentation mask and padding the background with all green pixels. This can be considered as an additional approach for data augmentation, which helps the CNN to focus on the pollen grain in the image, as well as ignoring the remaining elements present in the background.
AlexNet
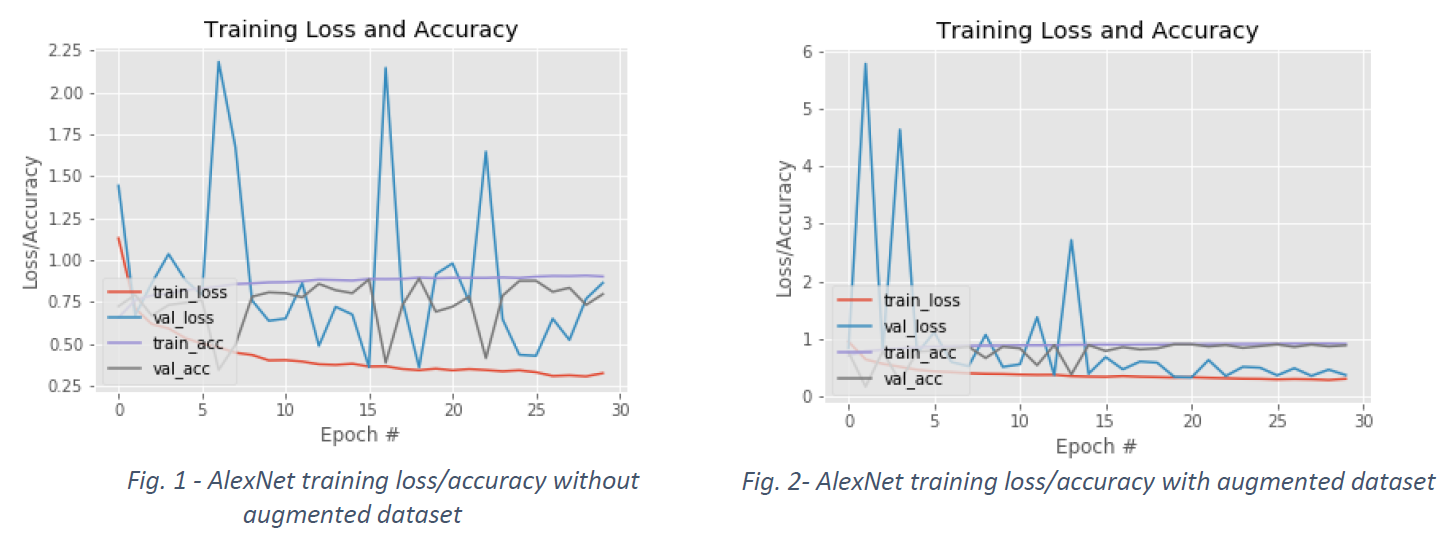
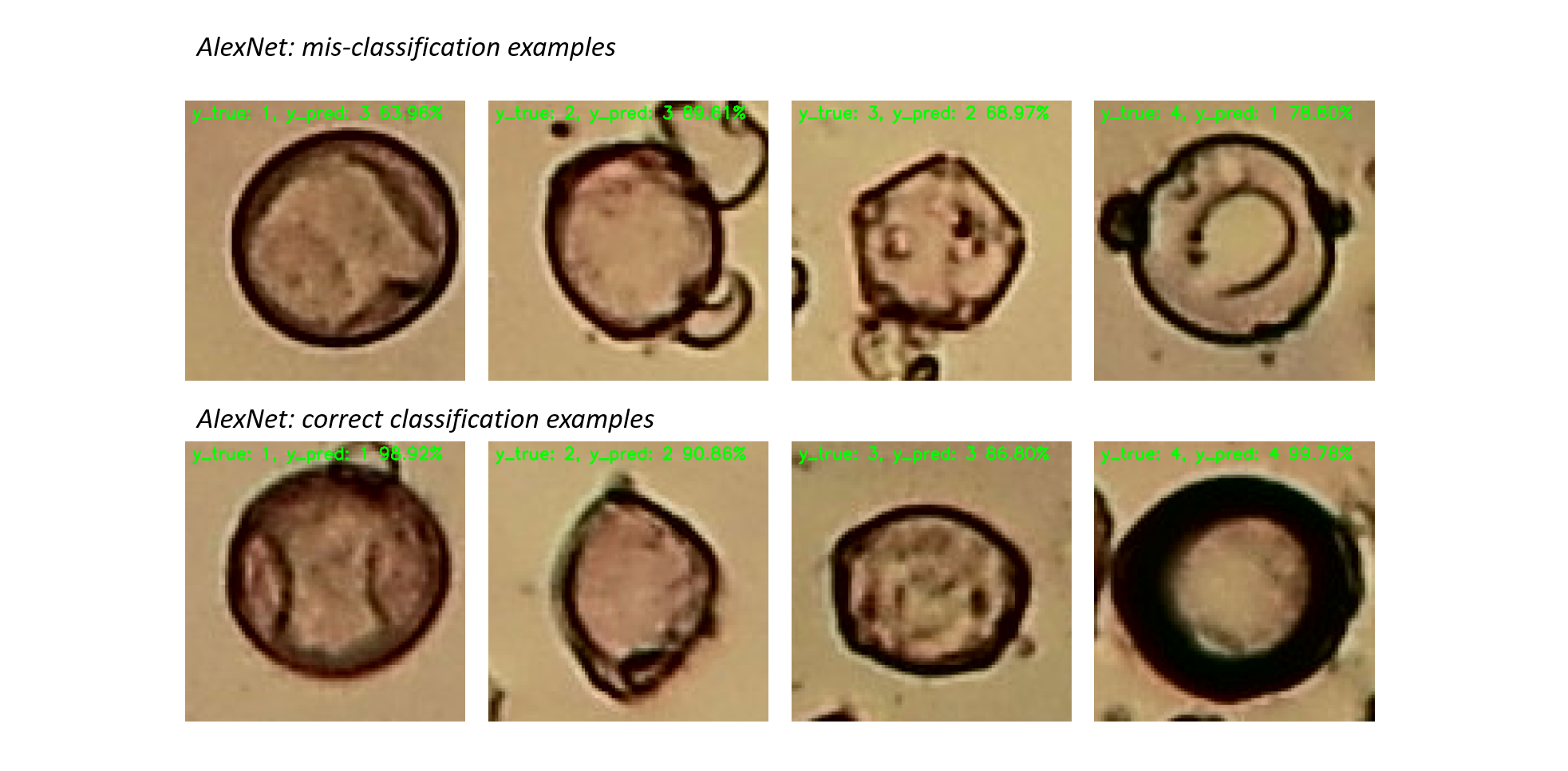
Fig. 1 and Fig. 2 show the performance plots related to the training of AlexNet considering the standard and the augmented dataset, respectively. In particular, each plot shows the loss and accuracy on the training and validation data over 30 epochs. It can be observed that the use of the augmented dataset, beside improving the model performances, helps in maintaining more stable the loss and accuracy fluctuation over the epochs, after just 5 epochs. Table 3 and Table 4 detail the accuracy and F1 results measured on the test set every 10 epochs, considering the standard and the augmented dataset, respectively. AlexNet outperforms the standard ML approaches only when the augmented dataset is considered (see Table 4).


SmallerVGGNet

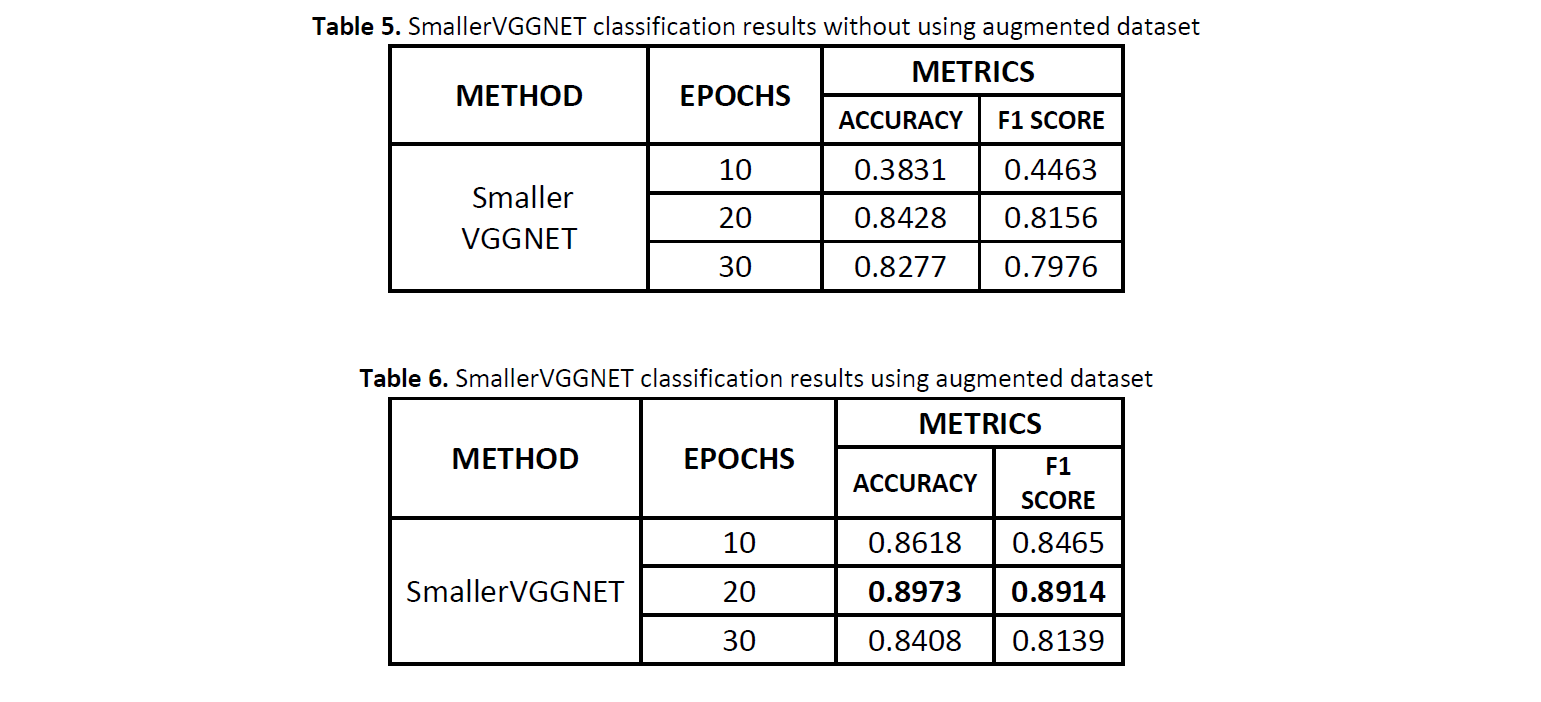
Fig. 3 and Fig. 4 show the performance plots related to the training of SmallerVGGNET considering the standard and the augmented dataset, respectively. Also in this case the use of the augmented dataset improves the model performances and helps in maintaining more stable the loss and accuracy fluctuation over the epochs. Table 5 and Table 6 detail the accuracy and F1 results measured on the test set every 10 epochs, considering the standard and the augmented dataset, respectively. SmallerVGGNET trained on the augmented dataset outperforms all the previous approaches reaching an accuracy of 0.8973 and a F1 score of 0.8914 after 20 epochs (see Table 6).
The following figures show examples of good classification and mis-classification of AlexNet and SmallerVGGNET. Each example details the true and predicted class, as well as the confidence of the model.