Bellomo Dataset
The dataset has been generated using the NEW tool for Unity 3D proposed in our paper:
S. A. Orlando, A. Furnari, G. M. Farinella - Egocentric Visitor Localization and Artwork Detectionin Cultural Sites Using Synthetic Data.
Submitted in Pattern Recognition Letters on Pattern Recognition and Artificial Intelligence Techniques for Cultural Heritage special issue, 2020.
The tool used to generate the dataset is available at this link  ).
).
The dataset has been generated using the "Galleria Regionale Palazzo Bellomo" 3D model scanned with Matterport.
By using this model, we simulated egocentric navigations of 4 navigations with a first clockwise navigation and a second counterclowise navigation in accord to
the room layout of the museum.
In each room the virtual agent have to visit 5 observation points situated in front of each artworks of the museum.
We acquired (at 5 fps) 99, 769 images.
The tool automatically labels each frame according to the 6 Degrees of Freedom (6DoF) of the camera: 1) camera position (x, y, z) and 2) camera orientation in quaternions (w, p, q, r).
Specifically we converted the 6DoF of the camera pose in 3DoF format taking in consideration:
- the camera position represented by the coordinates x and z according to the left-handed coordinate system of Unity;
- the camera orientation
vector (u, v) which represent the rotation angle along the y-axis.

| Navigations | 1 | 2 | 3 | 4 | Overall images |
|---|---|---|---|---|---|
| # of Frames | 24, 525 | 25, 003 | 26, 281 | 23, 960 | 99, 769 |
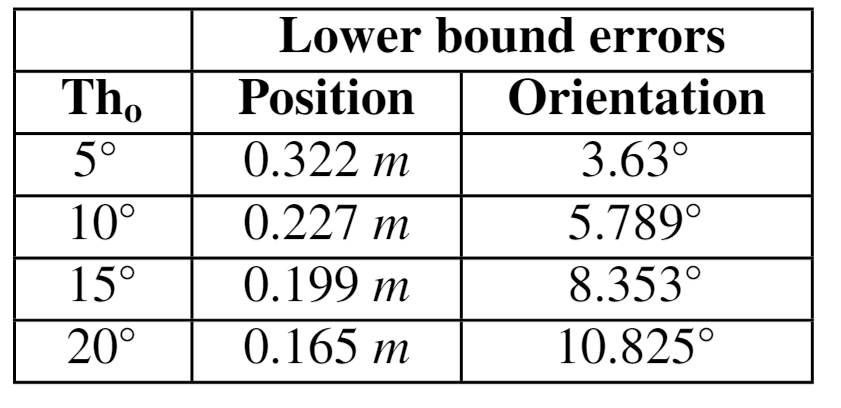
To evaluate the quality of proposed dataset in term of usefulness fo localization task, for each test sample we perform an optimal nearest neighbor search associating it to the closest pose in the training set.

List of artworks labeled in the Bellomo dataset, with the related coordinates in the 3D model and the RGB color codes used to produce the semantic masks.