EgoCart: a Benchmark Dataset for Large-Scale Indoor Image-Based Localization in Retail Stores
Emiliano Spera, Antonino Furnari, Sebastiano Battiato, Giovanni Maria Farinella
We consider the task of localizing shopping carts in a retail store from egocentric images. Addressing this task allows to infer information on the behavior of the customers to understand how they move in the store and what they pay more attention to. To study the problem, we propose a large dataset of images collected in a real retail store. The dataset comprises 19,531 RGB images along with depth maps, ground truth camera poses, as well as class labels specifying the areas of the store in which each image has been acquired. We release the dataset to the public to encourage research in large-scale imagebased indoor localization and to address the scarcity of large datasets to tackle the problem. We hence perform a benchmark of several image-based localization techniques exploiting images and depth information on the proposed dataset. In our study, both localization performances and space/time requirements are compared. The results show that, while state-of-the-art approaches allow to achieve good results, there is space for improvement. This work investigates the new problem of image-based egocentric shopping cart localization in retail stores. The contribution of our work is two-fold. First, we propose a novel large-scale dataset for image-based egocentric shopping cart localization. The dataset has been collected using cameras placed on shopping carts in a large retail store. It contains a total of 19,531 image frames, each labelled with its six Degrees Of Freedom pose. We study the localization problem by analysing how cart locations should be represented and estimated, and how to assess the localization results. Second, we benchmark different image-based techniques to address the task. Specifically, we investigate two families of algorithms: classic methods based on image retrieval and emerging methods based on regression. Experimental results show that methods based on image retrieval largely outperform regression-based approaches. We also point out that deep metric learning techniques allow to learn better visual representations w.r.t. other architectures, and are useful to improve the localization results of both retrieval-based and regression-based approaches. Our findings suggest that deep metric learning techniques can help bridge the gap between retrieval-based and regression-based methods.
Demo
The video shows the performance of the 1-NN approach based on image representations obtained using deep metric learning (Triplet Networks). On the right, we report the query image (top) and the closest training image selected by the 1-NN (bottom). On the left, we report all the 2D positions of the training samples (black points) and the ground truth positions of test video (red line). At each time step, a circle indicates the inferred position. The color of the circle indicates the position error committed by the algorithm (see color bar on the right for reference). We also report a segment to link the inferred position to the ground truth one.
Papers
@article{spera2019egocart, journal = {IEEE Transactions on Circuits and Systems for Video Technology}, title = {EgoCart: a Benchmark Dataset for Large-Scale Indoor Image-Based Localization in Retail Stores}, author = {Emiliano Spera and Antonino Furnari and Sebastiano Battiato and Giovanni Maria Farinella}, url = {home/_paper/spera2021egocart.pdf}, year = {2021}, pages = {1253-1267}, issue = {4}, volume = {31} }
@inproceedings{spera2018egocentric, year = {2018}, booktitle = {International Conference on Pattern Recognition (ICPR)}, title = {Egocentric Shopping Cart Localization}, author = {Emiliano Spera and Antonino Furnari and Sebastiano Battiato and Giovanni Maria Farinella}, url = {home/_paper/egocentric%20shopping%20cart%20localization.pdf} }
Dataset
The proposed dataset has been built using frames extracted from nine different videos acquired in a retail store with an extension of 782 m2. The videos have been acquired with two different zed-cameras mounted on a shopping cart with their focal axes parallel to the floor of the store. Each video has been temporally sub-sampled at 3 fps. The overall dataset consists of 19,531 pairs of RGB images and depth. Each pair is labeled with the related 3DOF pose and the related area of the store (class label). The dataset is divided into training and test sets. The two subsets have been obtained considering respectively 6 videos for training (13,360 frames) and 3 videos for test (6,171 frames). Each of the subsets contains images covering the entire store.
DOWNLOAD DATASET
DOWNLOAD CAMERA PARAMETERS

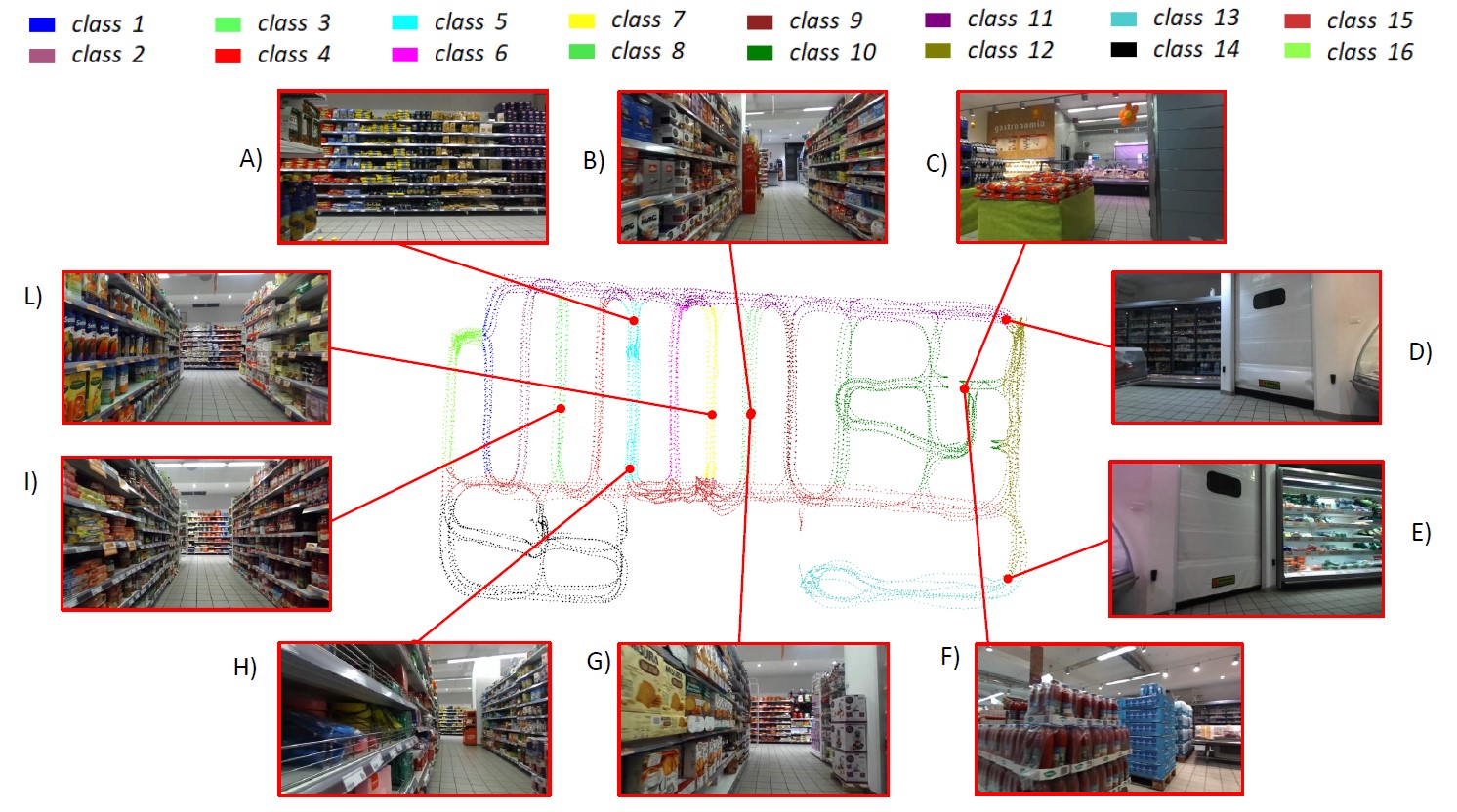
Some examples from the proposed dataset along with their positions. Samples belonging to different classes are denoted by different colors in the 2D map. The dataset offers an interesting test bed for large-scale indoor localization. Indeed it contains several hard examples: A) and H) contain the same shelf at different scales, B) and G) denote frames in the same corridor with opposite directions, C) and F) are frames with the same position but different orientations, D) and E) denote images with different positions, but similar content, L) and I) are images of two different corridors with high visual similarity.



