Dataset
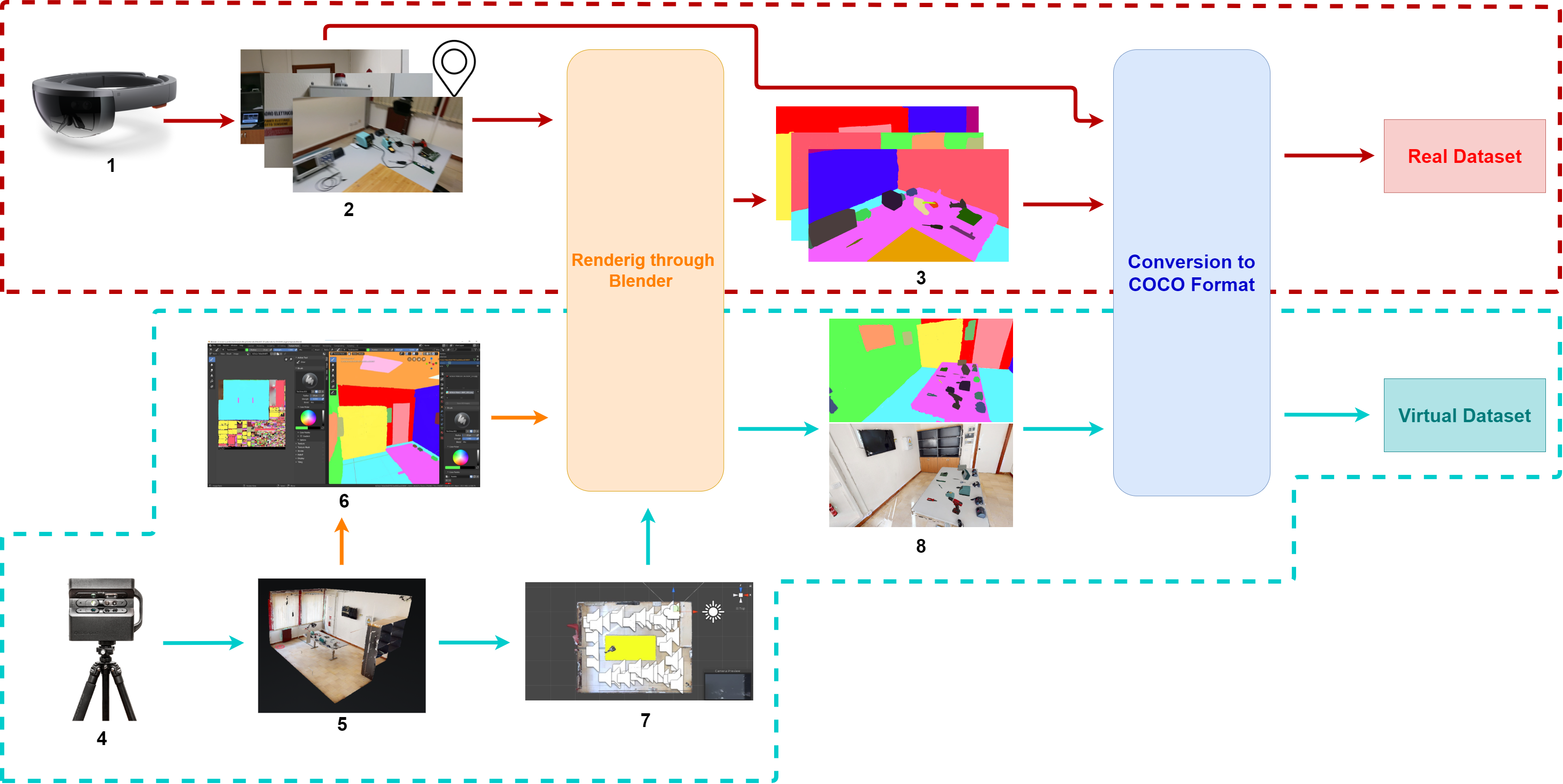
Dataset generation pipeline
To study the considered problem, we have created a dataset comprised of two parts: real images with segmented masks manually annotated and synthetic images with automatically generated annotations.
Red box: generation of the real dataset: (1) acquisition of real images using HoloLens2; (2) extraction of frames and related camera poses; (3) annotation of the segmentation masks.
Blue box: generation of the synthetic dataset: (4) acquisition of the 3D model using a Matterport3D scanner; (5) generation of the 3D model; (6) semantic labelling of the 3D model using Blender; (7) generation of a random tour inside the 3D model; (8) generation of synthetic frames and semantic labels. (Rendering through Blender) the 3D model and the positions are processed by a script for the generation of frames and semantic labels; (Conversion in COCO format) semantic labels are processed by a script for extracting JSON annotations in COCO format.
Real Dataset
- 1665 RGB Images
- 1665 Semantic Images
- 1665 Panoptic Images
- Image Resolution: 1280x720
- 35 classes represented
- Download

- 25.079 RGB Images
- 25.079 Semantic Images
- 25.079 Panoptic Images
- Image Resolution: 1280x720
- 35 classes represented
- Download






