Baselines & Proposed Approaches
Task
Differently from the standard object detection task which aims to detect and recognize all the objects present in the scene, we define attended object detection as the task of detecting and recognizing only the object observed by the camera wearer from the analysis of the RGB image and gaze. Formally, let \(O = \{o_1, o_2, \ldots, o_n\}\) be the set of objects in the image and let \(C = \{c_1, c_2, \ldots, c_n\}\) be the corresponding set of object classes. Given an image, the proposed task consists in detecting the attended object \(o_{att} \in O\), predicting its bounding box coordinates \((x_{att}, y_{att}, w_{att}, h_{att})\) and assigning it the correct class label \(c_{att}\).
Full supervision
At this supervision level, we assume that bounding boxes around all objects, plus gaze are available at training time, while only gaze is available at test time. We consider a baseline approach based on an object detector trained to detect and recognize all objects in the image. At test time, the attended object is predicted selecting the predicted object whose center is closest to the estimated gaze. In our experiments we consider both Faster-RCNN and RetinaNet as detectors
Weak Supervision
At this supervision level, we assume that gaze, plus some form of weak supervision on the attended object is available at training time, while only gaze is available at test time. We consider three versions of this supervision level, based on the “weakness” of the provided labels. The three versions are described in the paper
Unsupervised
At this supervision level, we tested salient object detection methods as baselines, despite challenges in determining the attended object's granularity. This approach reduces the need for extensive labeling. Attended object detection, though similar to salient object detection, may not always focus on the most visually distinct object. We also considered the "Segment Anything Model" (SAM) due to its recent success.

Proposed Approaches
Besides the considered baselines, we propose two new approaches to tackle attended object detection at the different weakly supervised levels, which offer the best trade-off in terms of performance and needed amount of supervision, as shown in our experiments. Specifically, we propose a box coordinates regressor algorithm which can be trained when bounding boxes around attended objects are available and a weakly supervised attended object detection approach which can be used when only the attended object class is available as a form of supervision
Box coordinates regressor.
This method predicts the attended object's bounding box using the user's 2D gaze coordinates as input, in contrast to traditional object detection techniques. It exclusively trains on the attended object's box, reducing required labels. The approach uses a ResNet18 feature extractor, followed by convolutional modules for estimating coordinates and dimensions, producing predictions based on gaze location. During training, Mean Squared Error loss is employed. At test time, the offset is added to the gaze position for the object's bounding box, determined by the size vector. A separate module classifies the object. If it predicts "other," the object is discarded. This approach can be trained with gaze + attended object bounding box data or gaze + attended object bounding box + class data.

Fully Convolutional attended object detection
The sliding window approach faces a significant limitation due to its slow inference speed, driven by evaluating numerous windows. To address this, we adapted the ResNet18 model described in the same section. We replaced the Global Average Pooling operation with a 1X1 convolutional layer, enabling the model to predict a semantic segmentation mask for the entire image in a single forward pass. After initial coarse segmentation, up-sampling to the original resolution refines the segmentation mask. Utilizing the box fitting method discussed, we derive the predicted bounding box of the attended object. This approach, though faster than the sliding window approach, incurs a performance decrease, potentially due to domain shift from training on patches and evaluating on full images. To mitigate this issue, we fine-tuned the model, minimizing the average Kullback-Leibler (KL) distance between pixel-wise probability distributions, as outlined.

Results
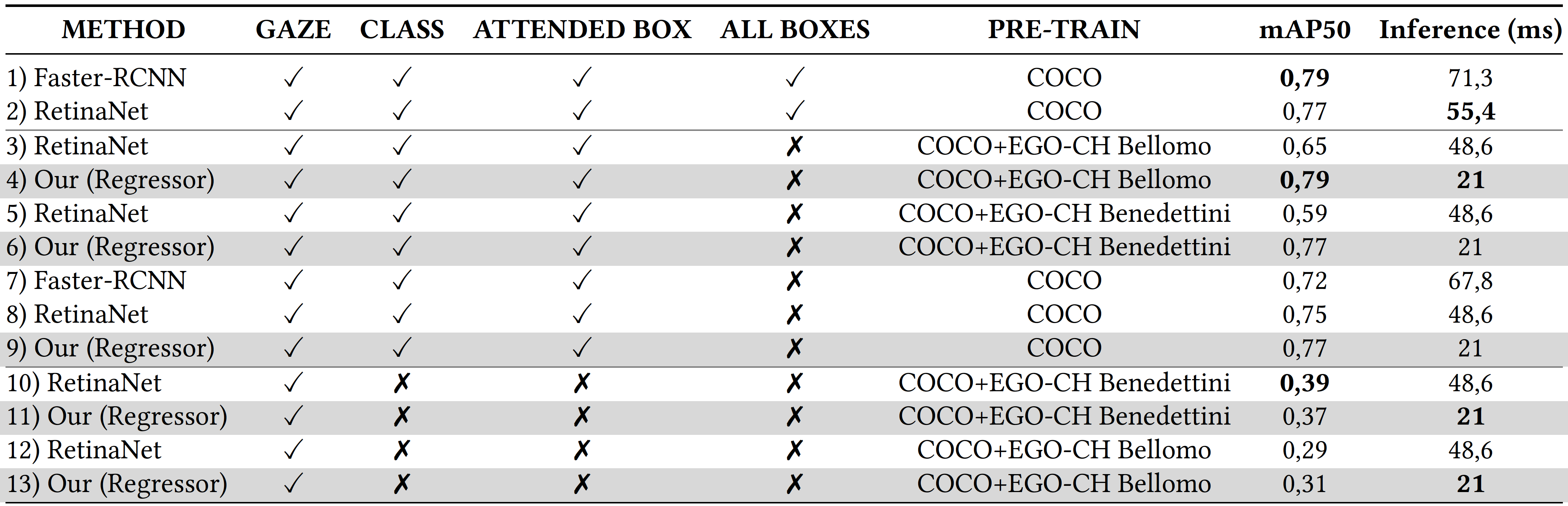
Results obtained by the compared approaches, when all classes are considered, for each level of supervision (from the highest to the lowest). In bold the best results by supervision group.
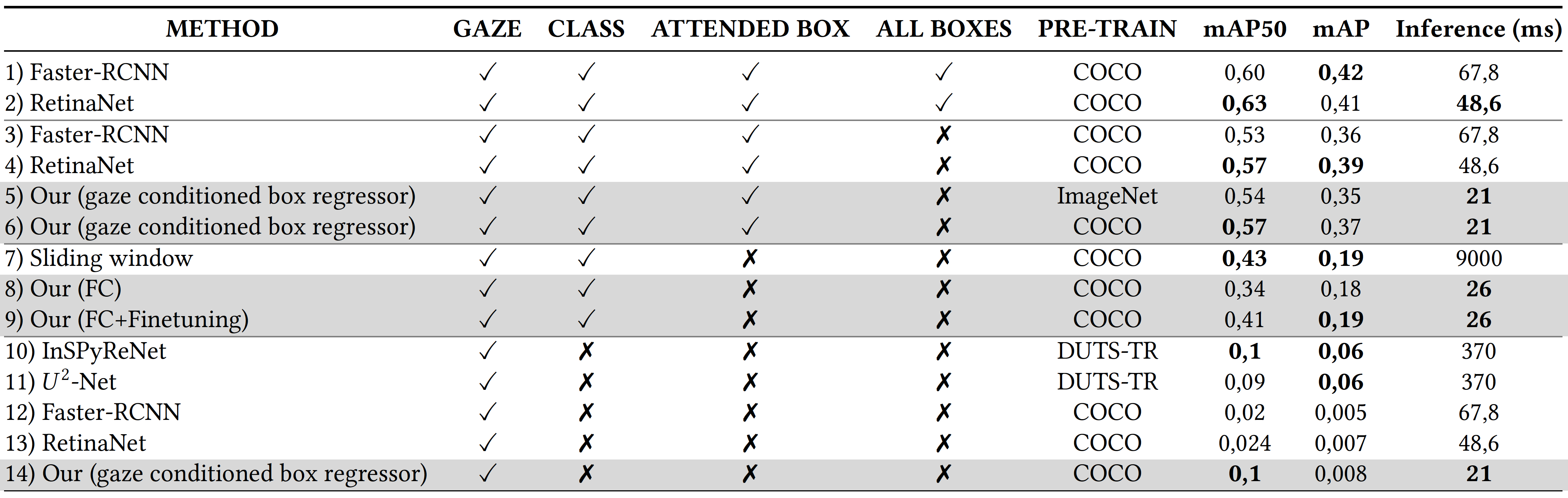
Results obtained adding a pre-training step with similar-context datasets by the compared approaches, when all classes are considered, for each level of supervision (from the highest to the lowest). In bold the best results by supervision group.

Results obtained by the compared approaches, when a generic "object" category is considered, for each level of supervision (from the highest to the lowest). In bold the best results by supervision group.