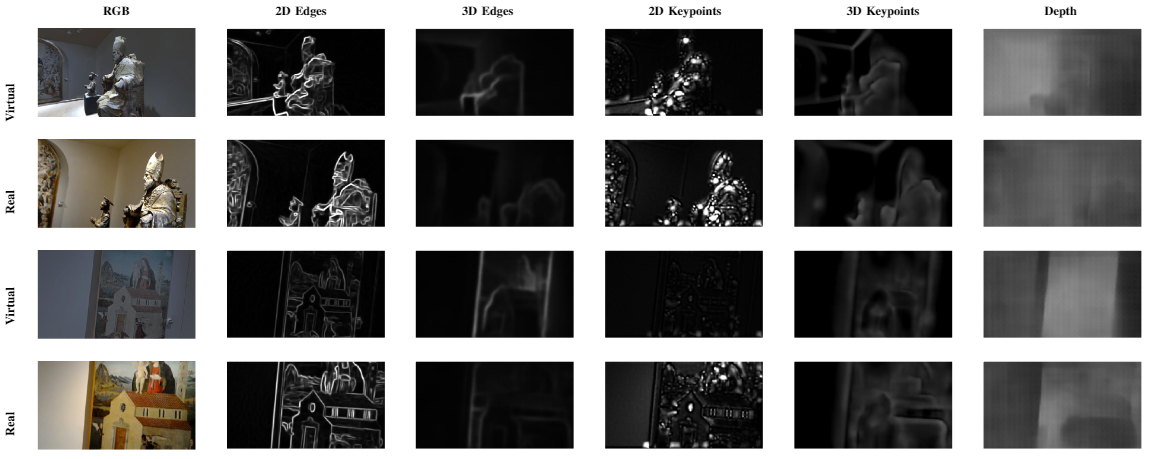
Virtual dataset - Bellomo Dataset
The dataset has been generated using the tool proposed in the paper:
S. A. Orlando, A. Furnari, G. M. Farinella - Egocentric Visitor Localization and Artwork Detectionin Cultural Sites Using Synthetic Data.
Submitted in Pattern Recognition Letters on Pattern Recognition and Artificial Intelligence Techniques for Cultural Heritage special issue, 2020.
The dataset has been generated using the "Galleria Regionale Palazzo Bellomo" 3D model scanned with Matterport, and includes
simulated egocentric navigations of 4 navigations.
Each frames has been labeled with the 3DOF and the room in which the virtual agent is during the acquisition.
The context of the museum are 11. The figure below shows the map of the museum.

Fig. 2: Map of Palazzo Bellomo with marked contexts.
- the camera position represented by the coordinates x and z according to the left-handed coordinate system of Unity;
- the camera orientation
vector (u, v) which represent the rotation angle along the y-axis.
| Navigations | 1 | 2 | 3 | 4 | Overall images |
|---|---|---|---|---|---|
| # of Frames | 24, 525 | 25, 003 | 26, 281 | 23, 960 | 99, 769 |
Table 1: Dataset detail of Palazzo Bellomo.