What Would You Expect? Anticipating Egocentric Actions with Rolling-Unrolling LSTMs and Modality Attention
Antonino Furnari, Giovanni Maria Farinella
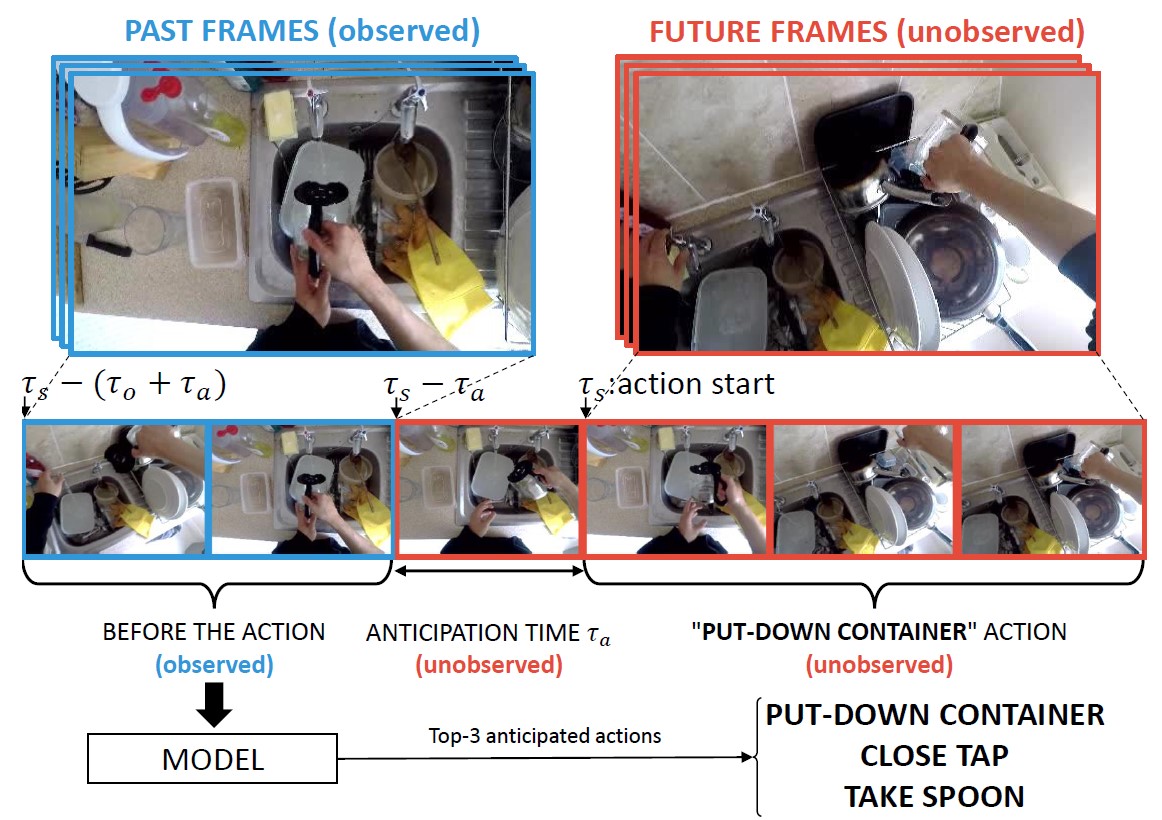
The goal of an action anticipation method is to predict egocentric actions from an observation of the past. The input of the model is a video segment to seconds long (observation time) preceding the start time of the action ts by ta seconds (anticipation time). Since the future is naturally uncertain, action anticipation methods usually predict more than one possible actions (e.g., the TOP-3 predictions).
Method
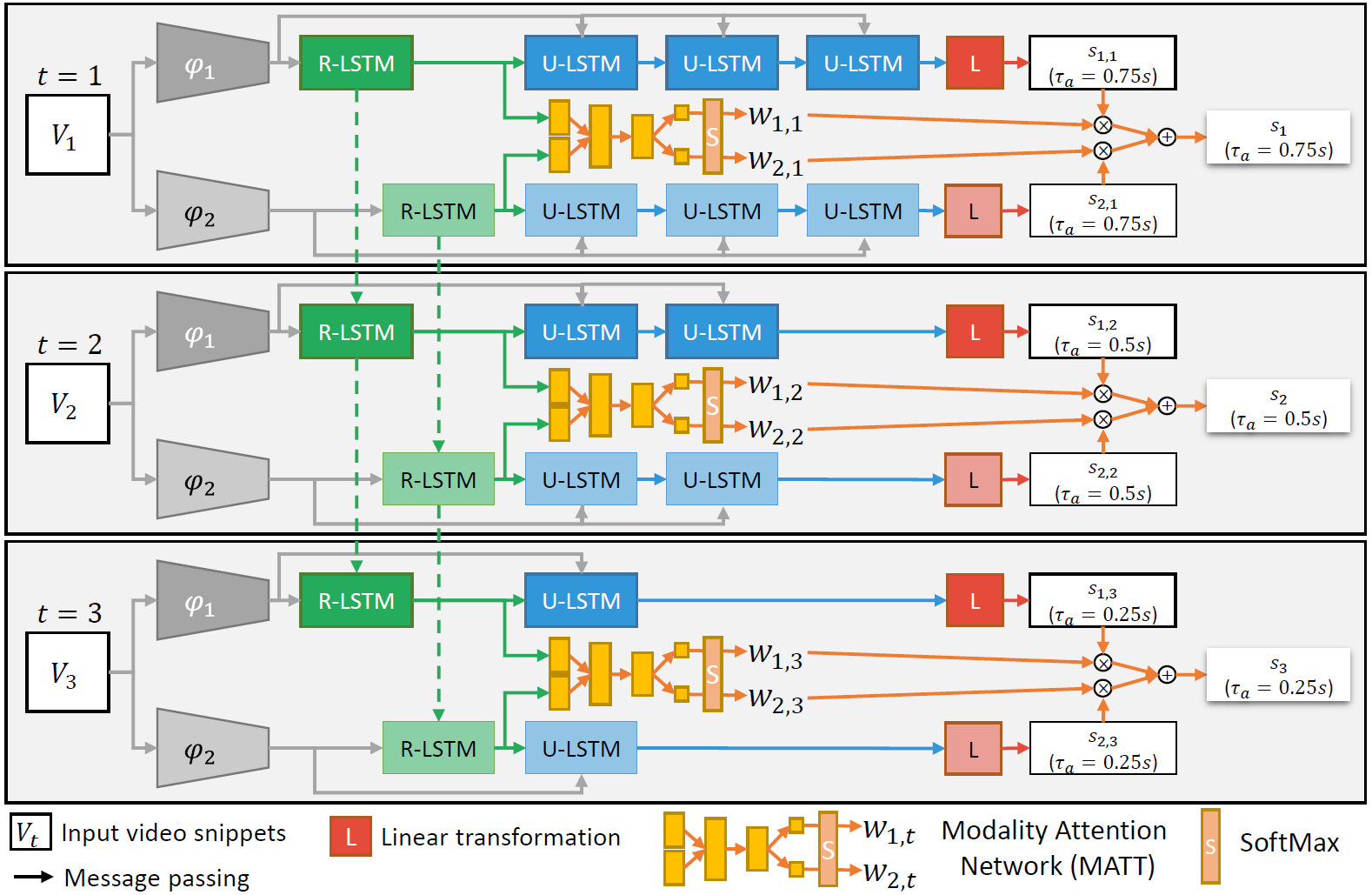
The proposed method uses two LSTMS to 1) encode streaming observations, 2) make predictions about the future. The first LSTM, termed "Rolling LSTM" processes a frame representaion at each time step, with the aim of continuously encoding the past. When a new prediction is required, the "Unrolling LSTM" is initialized from the internal state of the Rolling LSTM. The Unrolling LSTM is hence unrolled for a number of time-step equal to those needed to reach the beginning of the action to formulate the final prediction. The proposed method processes information according to multimple modalities (RGB frames, Optical Flows and Object-based features). The predictions made by the different modalities are combined by a novel modality attention mechanism which learns to weigh the different modalities depending on the observed sample. See the paper for more details.
Videos
Egocentric Action Anticipation Examples
Early Action Recognition Examples
Paper
A. Furnari, G. M. Farinella, Rolling-Unrolling LSTMs for Action Anticipation from First-Person Video. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI). 2020. Paper
@article{furnari2020rulstm,
year = { 2020 },
title = { Rolling-Unrolling LSTMs for Action Anticipation from First-Person Video },
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) },
author = { Antonino Furnari and Giovanni Maria Farinella },
}
A. Furnari, G. M. Farinella, What Would You Expect? Anticipating Egocentric Actions with Rolling-Unrolling LSTMs and Modality Attention. International Conference on Computer Vision. 2019. Paper
@inproceedings{furnari2019rulstm,
title = { What Would You Expect? Anticipating Egocentric Actions with Rolling-Unrolling LSTMs and Modality Attention. },
author = { Antonino Furnari and Giovanni Maria Farinella },
year = { 2019 },
booktitle = { International Conference on Computer Vision },
}
Code
Please check out our code and models at https://github.com/fpv-iplab/rulstm.
Acknowledgement
This research is supported by Piano della Ricerca 2016-2018 linea di Intervento 2 of DMI of the University of Catania.

