Personal-Location-Based Temporal Segmentation of Egocentric Video for Lifelogging Applications
Antonino Furnari, Sebastiano Battiato, Giovanni Maria Farinella
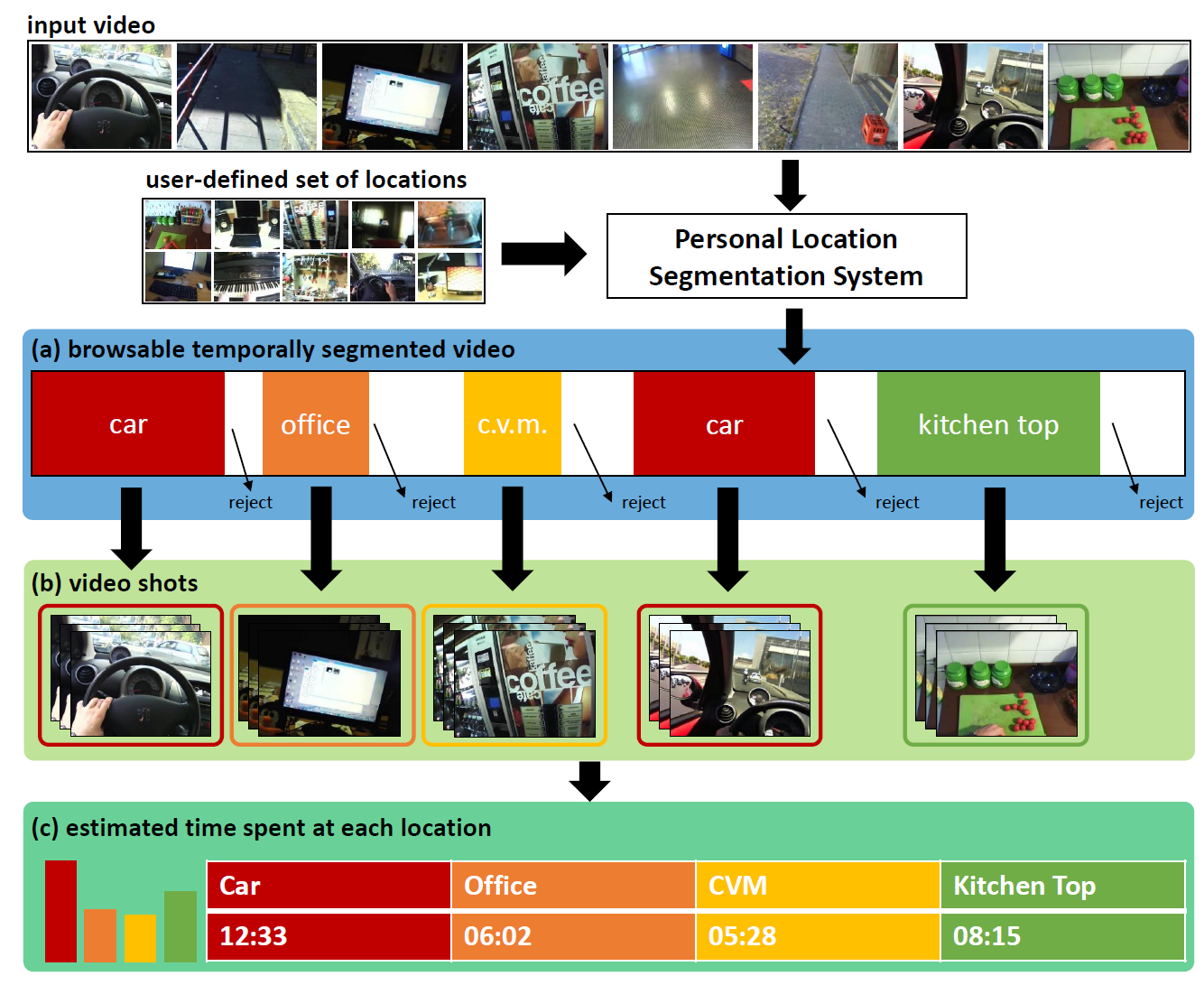
Scheme of the proposed temporal segmentation system. The system can be used to (a) produce a browsable temporally segmented egocentric video, (b) produce video shots related to given locations of interest, (c) estimate the amount of time spent at a specific location.
Demo
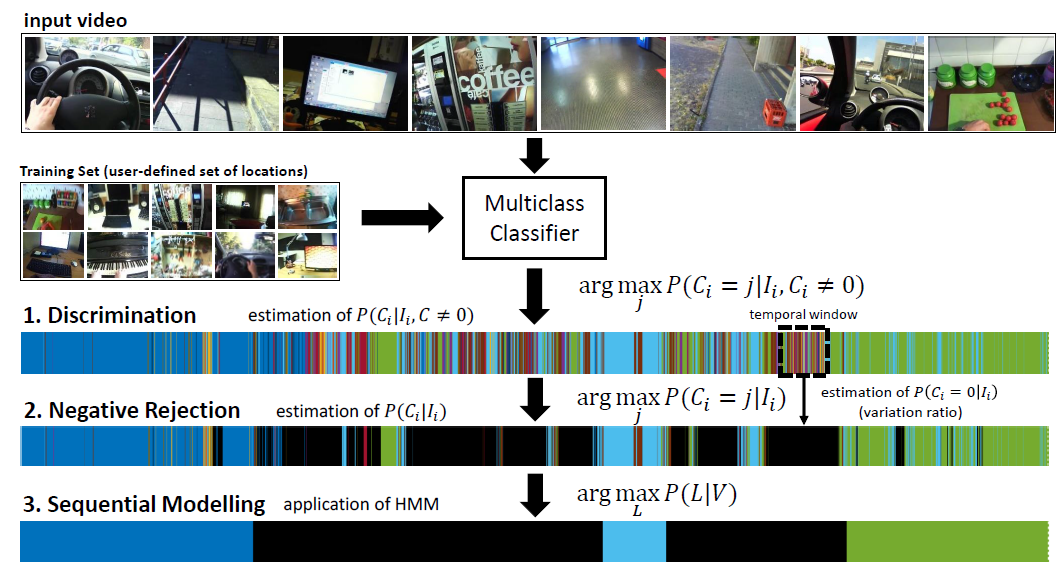
The proposed method aims at segmenting an input egocentric video into coherent segments. Each segment is related to one of the personal locations specified by the user or, if none of them apply, to the negative class. After an off-line training procedure (which relies only on positive samples provided by the user), at test time, the system processes the input egocentric video. For each frame, the system should be able to 1) recognize the personal locations specified by the user, 2) reject negative samples, i.e., frames not belonging to any of the considered personal locations, and 3) group contiguous frames into coherent video segments related to the specified personal locations. The method works in three steps, namely discrimination, negative rejection and sequential modeling.
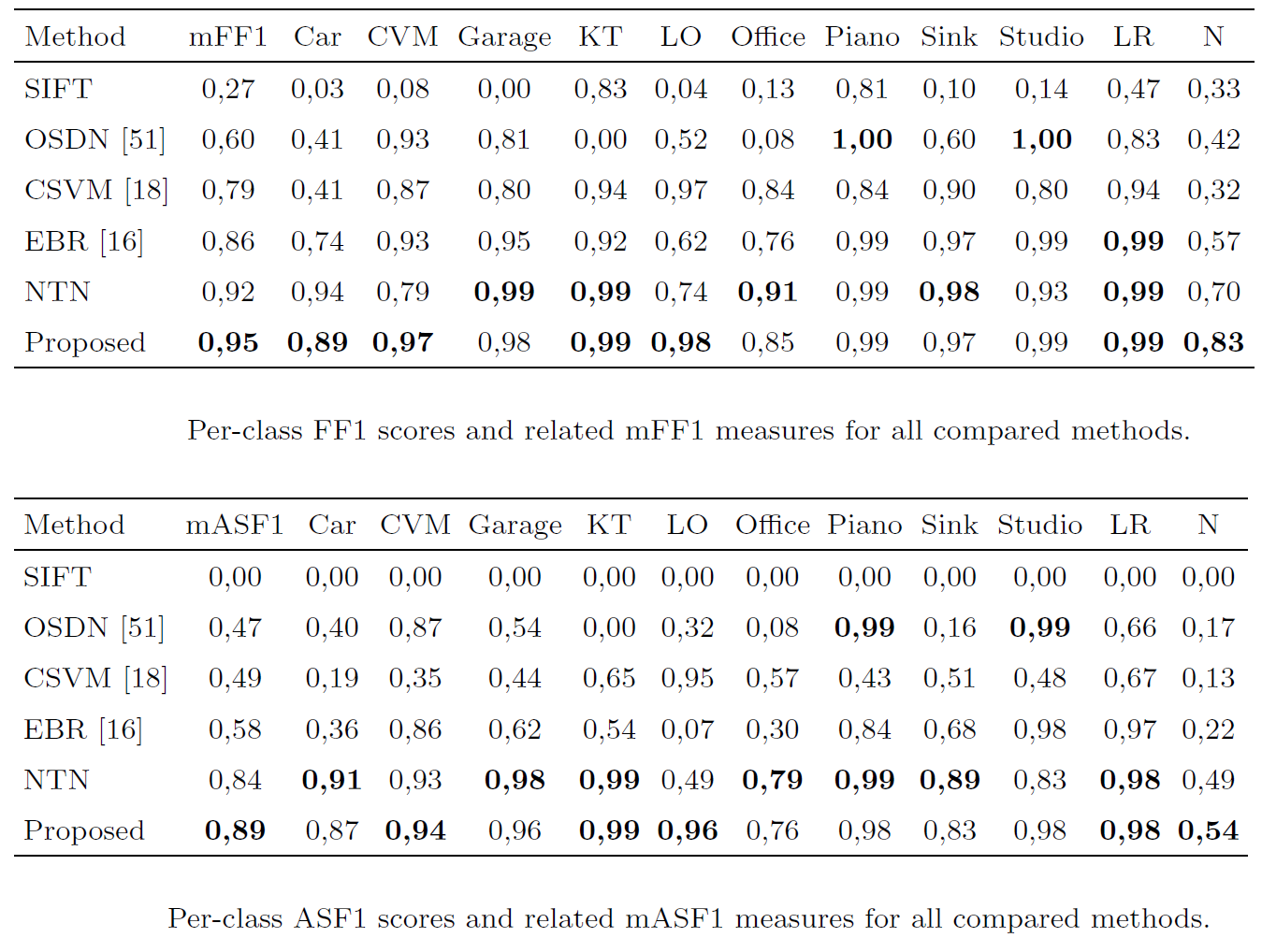
(see the paper for all details)
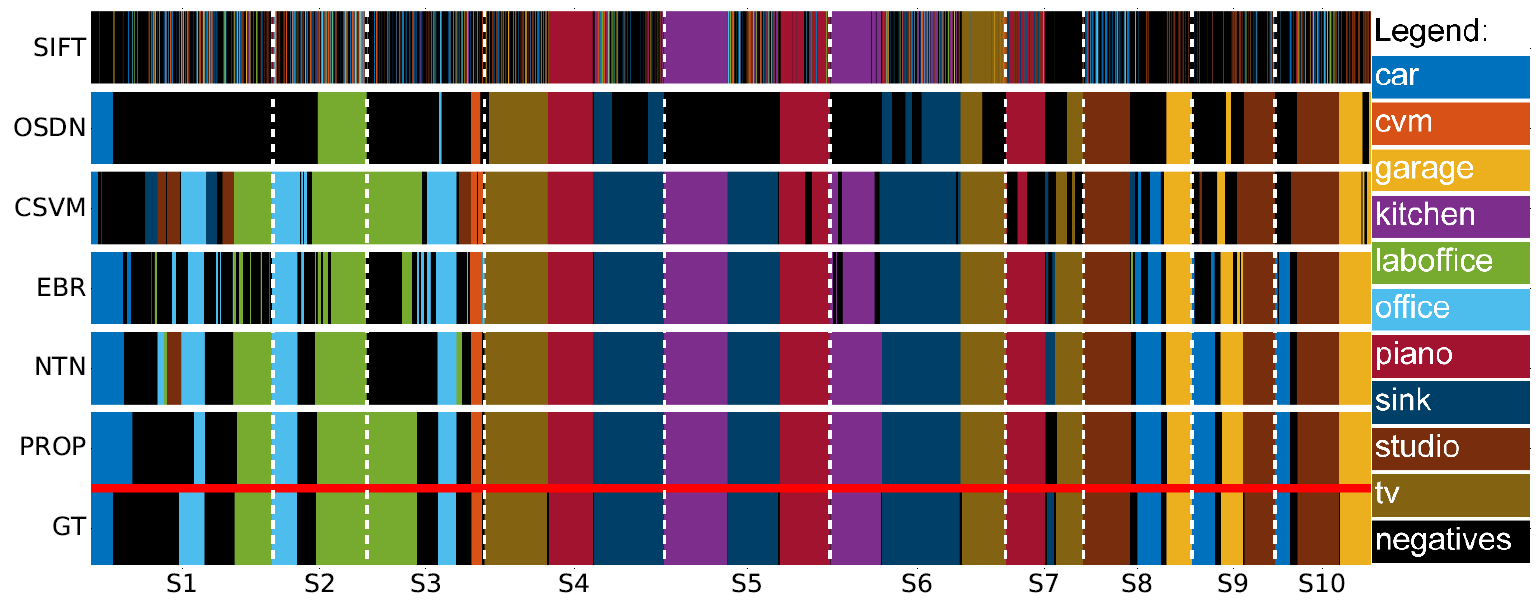
Color-coded segmentation results for qualitative assessment. The diagram compares the proposed method (PROP) with respect to temporal video segmentation approaches. The ground truth is denoted with GT.
Papers
[JVCI 2018] A. Furnari, S. Battiato, G. M. Farinella, Personal-Location-Based Temporal Segmentation of Egocentric Video for Lifelogging Applications . Journal of Visual Communication and Image Representation , 52 , pp. 1-12 . Download Paper
@article{furnari2018personal,
pages = { 1-12 },
volume = { 52 },
doi = { https://doi.org/10.1016/j.jvcir.2018.01.019 },
issn = { 1047-3203 },
author = { Antonino Furnari and Sebastiano Battiato and Giovanni Maria Farinella },
year = { 2018 },
journal = { Journal of Visual Communication and Image Representation },
title = { Personal-Location-Based Temporal Segmentation of Egocentric Video for Lifelogging Applications },
}
[EPIC 2016] A. Furnari, G. M. Farinella, S. Battiato, Temporal Segmentation of Egocentric Videos to Highlight Personal Contexts of Interest, International workshop on egocentric perception, interaction and computing (EPIC) in conjunction with ECCV 2016. Download Paper
@inproceedings {furnari2016temporal,
author = "Furnari, Antonino and Farinella, Giovanni Maria and Battiato, Sebastiano",
title = "Temporal Segmentation of Egocentric Videos to Highlight Personal Locations of Interest",
booktitle = "International Workshop on Egocentric Perception, Interaction and Computing (EPIC) in conjunction with ECCV",
year = "2016"
}
Dataset

We collected a dataset of egocentric videos considering ten different personal locations, plus various negative ones. The considered personal locations arise from a possible daily routine: Car, Coffee Vending Machine (CVM), Office, Lab Office (LO), Living Room (LR), Piano, Kitchen Top (KT), Sink, Studio, Garage. We acquired the dataset using a Looxcie LX2 camera equipped with a wide angular converter. This configuration allows to acquire videos at a resolution of 640 x 480 pixels and with a Field Of View of approximately 100°.
Since we assume that the user is required to provide only minimal data to define his personal locations of interest, the training set consists in 10 short videos (one per location) with an average length of 10 seconds per video.
The test set consists in 10 video sequences covering the considered personal locations of interest, negative frames and transitions among locations. Each frame in the test sequences has been manually labeled as either one of the 10 locations of interest or as a negative.
The dataset is also provided with an independent validation set which can be used to optimize the hyper-parameters of the compared methods. The validation set contains 10 medium length (approximately 5 to 10 minutes) videos in which the user performs some activities in the considered locations (one video per location). Validation videos have been temporally subsampled in order to extract 200 frames per location, while all frames are considered for training and test videos.
We also acquired 10 medium length videos containing negative samples from which we uniformly extract 300 frames for training and 200 frames for validation. Negative samples are provided in order to allow comparisons with methods which explicitly learn from negatives.
Code
We provide Python code related to this paper. The code implements:- The proposed SF1 performance measure (function
SF1); - The proposed negative rejection method (function
rejectNegatives); - An implementation of the Viterbi algorithm to implement sequential modelling (function
viterbi).
Acknowledgement
This research is supported by PON MISE - Horizon 2020, VEDI Project, Prog. n. F/050457/02/X32 - CUP: B68I17000800008 - COR: 128032.
We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.


