ABSTRACT
Semantic segmentation methods have achieved outstanding performance thanks to deep learning.
Nevertheless, when such algorithms are deployed to new contexts not seen during training, it is necessary to collect and label scene-specific data in order to adapt them to the new domain using fine-tuning.
This process is required whenever an already installed camera is moved or a new camera is introduced in a camera network due to the different scene layouts induced by the different viewpoints.
To limit the amount of additional training data to be collected, it would be ideal to train a semantic segmentation method using labeled data already available and only unlabeled data coming from the new camera.
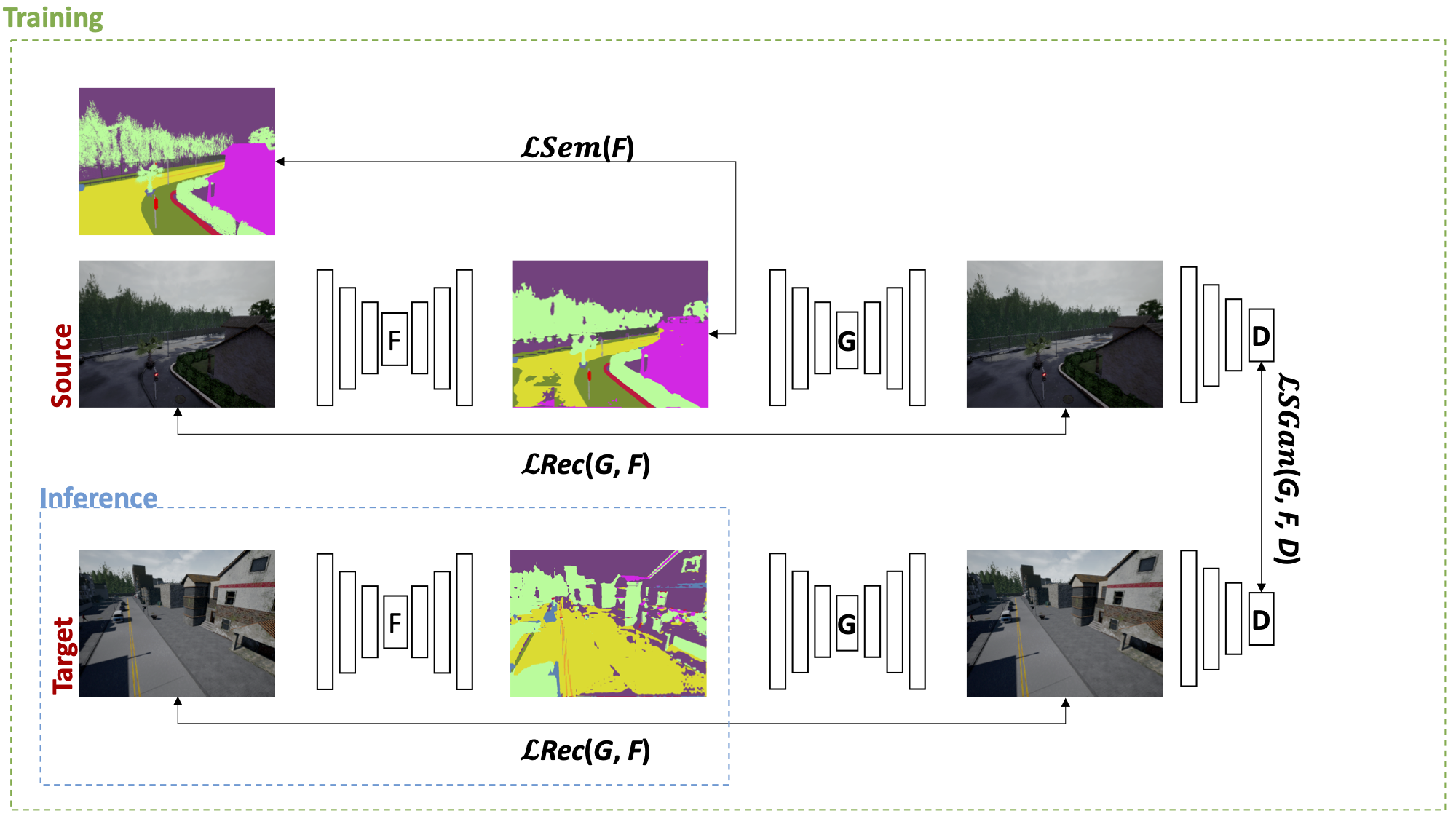
We formalize this problem as a domain adaptation task and introduce a novel dataset of urban scenes with the related semantic labels.
As a first approach to address this challenging task, we propose SceneAdapt, a method for scene adaptation of semantic segmentation algorithms based on adversarial learning.
Experiments and comparisons with state-of-the-art approaches to domain adaptation highlight that promising performance can be achieved using adversarial learning both when the two scenes have different but points of view, and when they comprise images of completely different scenes.