A Multi Camera Unsupervised Domain Adaptation Pipeline for Object Detection in Cultural Sites through Adversarial Learning and Self-Training
FPV@IPLAB - Department of Mathematics and Computer Science, University of Catania, Italy
Giovanni Pasqualino, Antonino Furnari, Giovanni Maria Farinella
Dataset
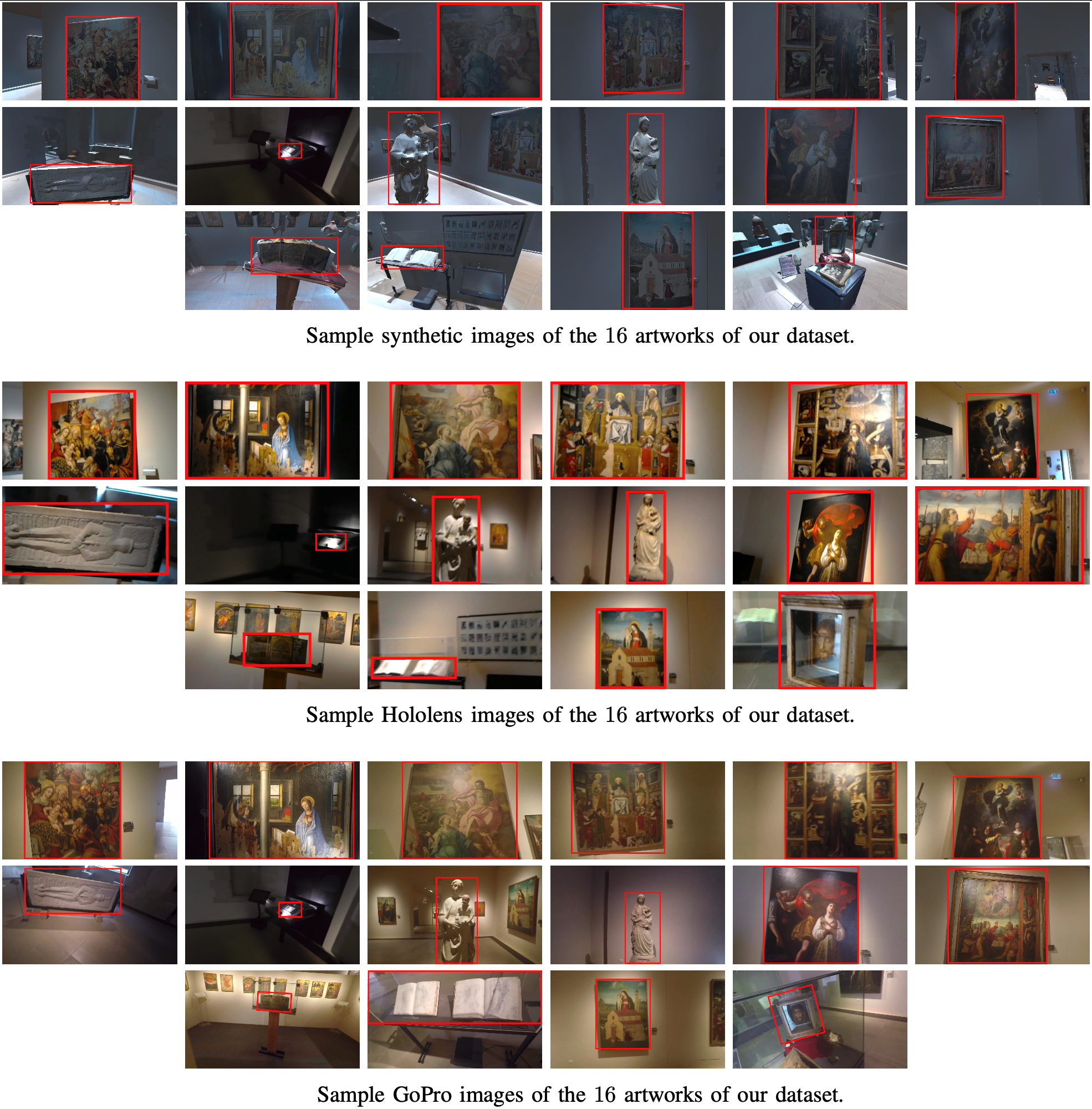
We propose a dataset of synthetic and real images related to 16 artworks present in "Galleria regionale Palazzo Bellomo" located in Siracusa, Italy. The dataset contains two set of images, synthetic and real which are divided has follows:
Synthetic Dataset
Real Hololens Dataset
Real GoPro Dataset
Instances Distributions
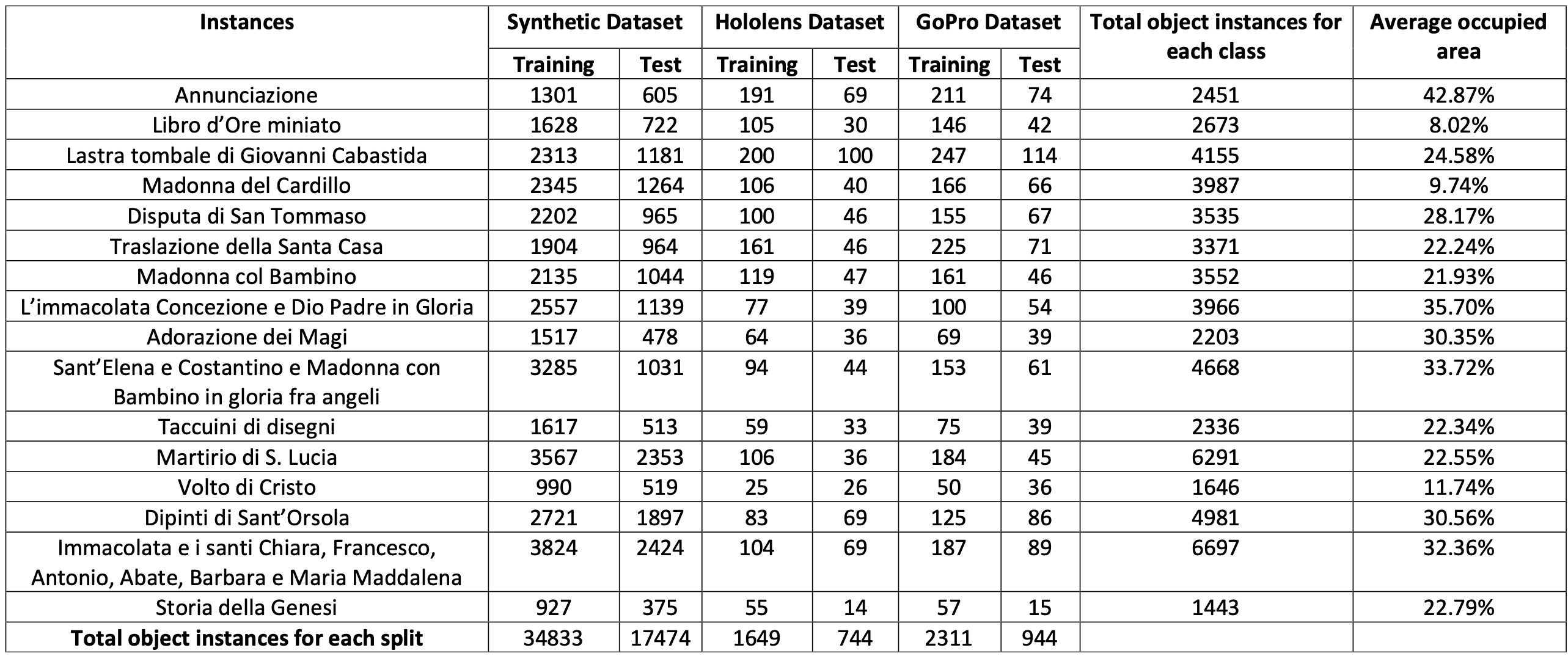
The average occupied area (last column) is the average percentage of the image occupied by the bounding boxes of the considered object class.
You can download the whole dataset and annotations at this link
Methods
We explore the following methods:
1) baseline approaches without adaption;
2) domain adaptation through image to image translation;
3) domain adaptation through feature alignment;
4) new multi target domain adaptation method STMDA-RetinaNet (see the figure below);
5) domain adaptation combining feature alignment and image to image translation.
Step 1
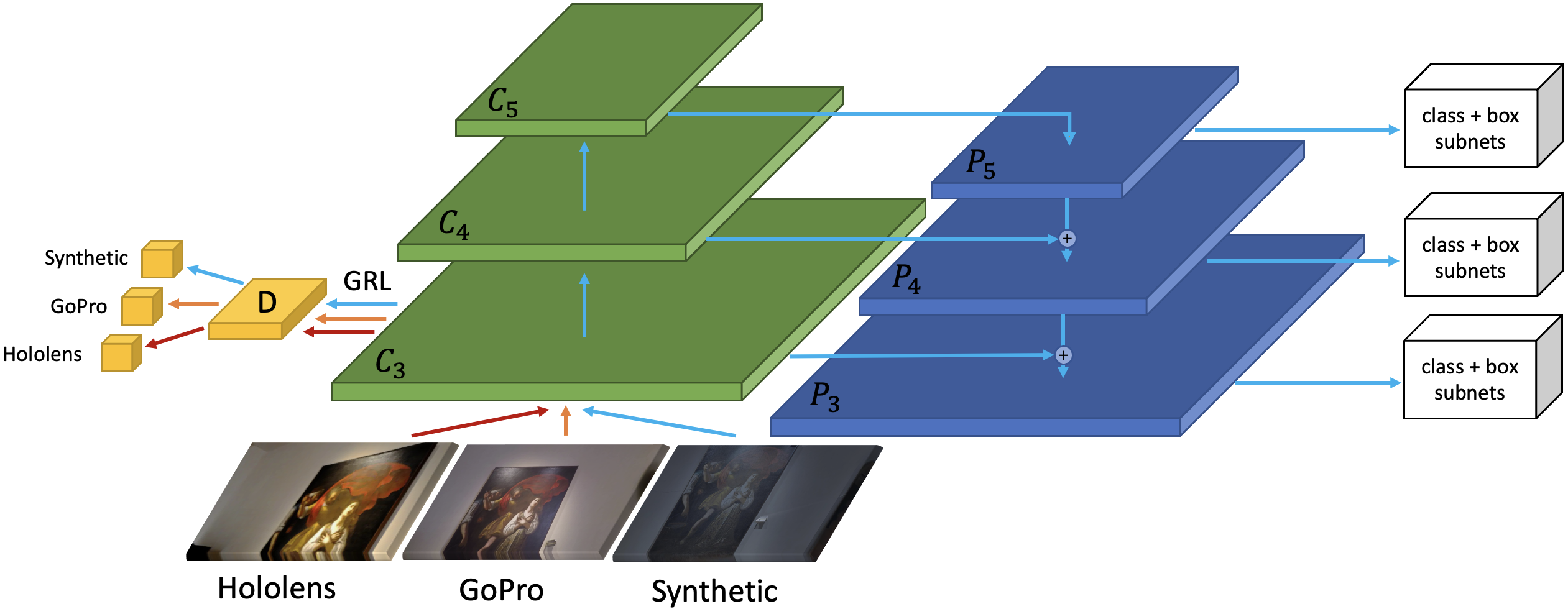
Architecture of the proposed MDA-RetinaNet model.
Step 2

Self-training module for MDA-RetinaNet.
Results
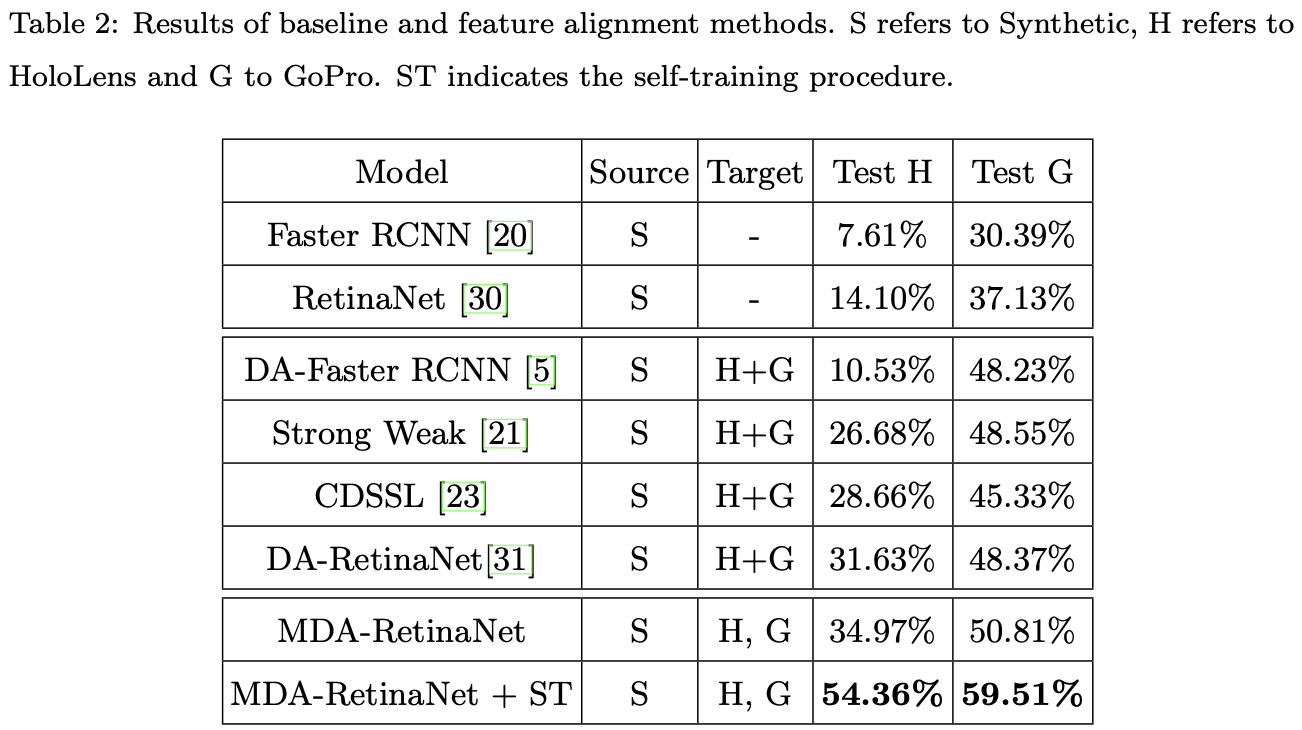
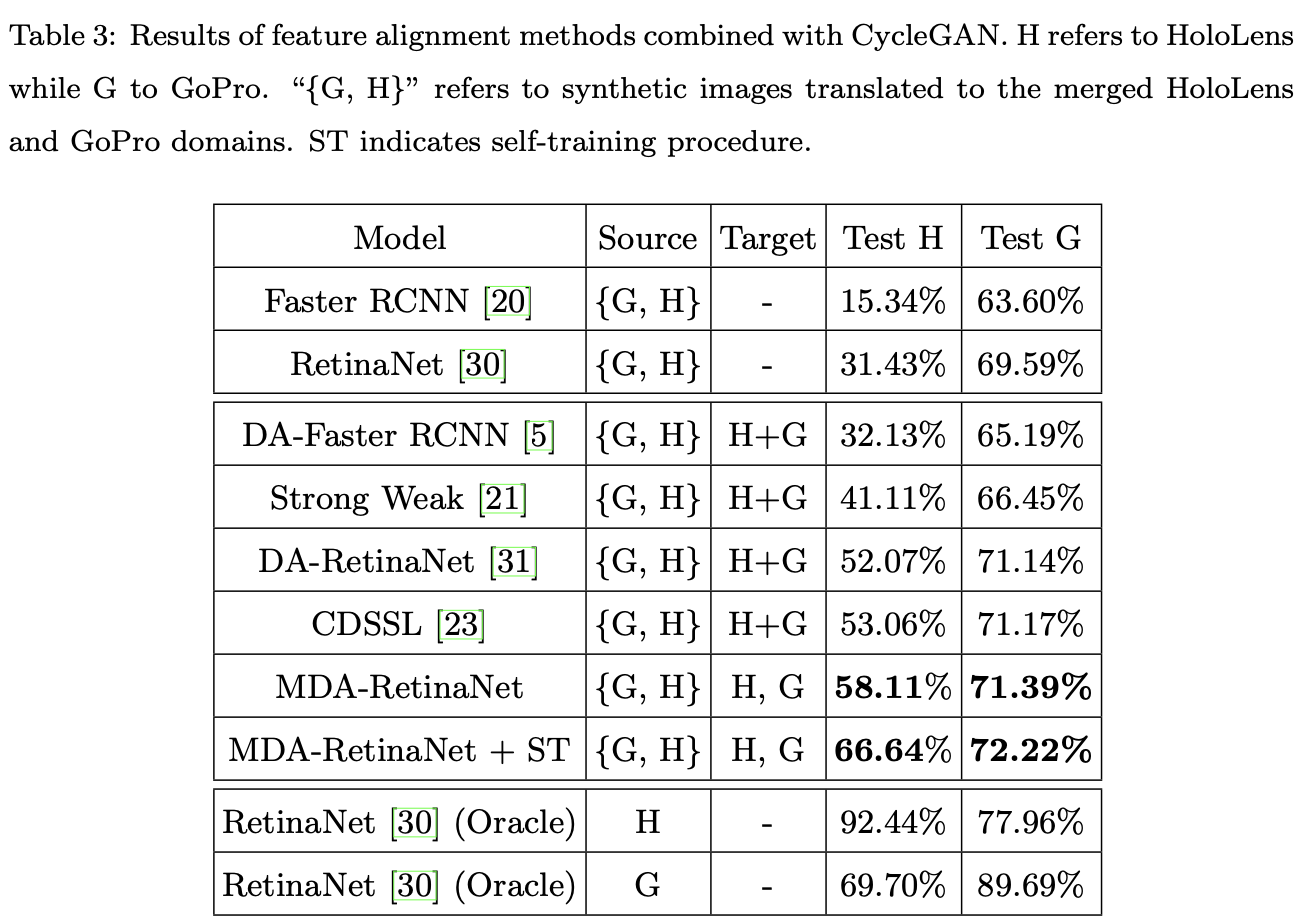
Qualitative Results

Paper
G. Pasqualino, A. Furnari, G. M. Farinella, A Multi Camera Unsupervised Domain Adaptation Pipeline for Object Detection in Cultural Sites through Adversarial Learning and Self-Training, Computer Vision and Image Understanding, 2022 Paper arXiv
@article{PASQUALINO2022103487,
title = {A multi camera unsupervised domain adaptation pipeline for object detection in cultural sites through adversarial learning and self-training},
journal = {Computer Vision and Image Understanding},
pages = {103487},
year = {2022}, issn = {1077-3142},
doi = {https://doi.org/10.1016/j.cviu.2022.103487},
url = {https://www.sciencedirect.com/science/article/pii/S1077314222000911},
author = {Giovanni Pasqualino and Antonino Furnari and Giovanni Maria Farinella}
}
Conference Paper
G. Pasqualino, A. Furnari, G. M. Farinella, "Unsupervised Multi-camera Domain Adaptation for Object Detection in Cultural Sites", International Conference on Image Analysis and Processing, 2022 Paper.Acknowledgement
This research has been supported by the project VALUE (N. 08CT6209090207 - CUP G69J18001060007) - PO FESR 2014/2020 - Azione 1.1.5., by Research Program Pia.ce.ri. 2020/2022 Linea 2 - University of Catania, and by MIUR AIM - Linea 1 - AIM1893589 - CUP E64118002540007.


