Next Active Object Prediction from Egocentric Video
Antonino Furnari, Sebastiano Battiato, Kristen Grauman, Giovanni Maria Farinella
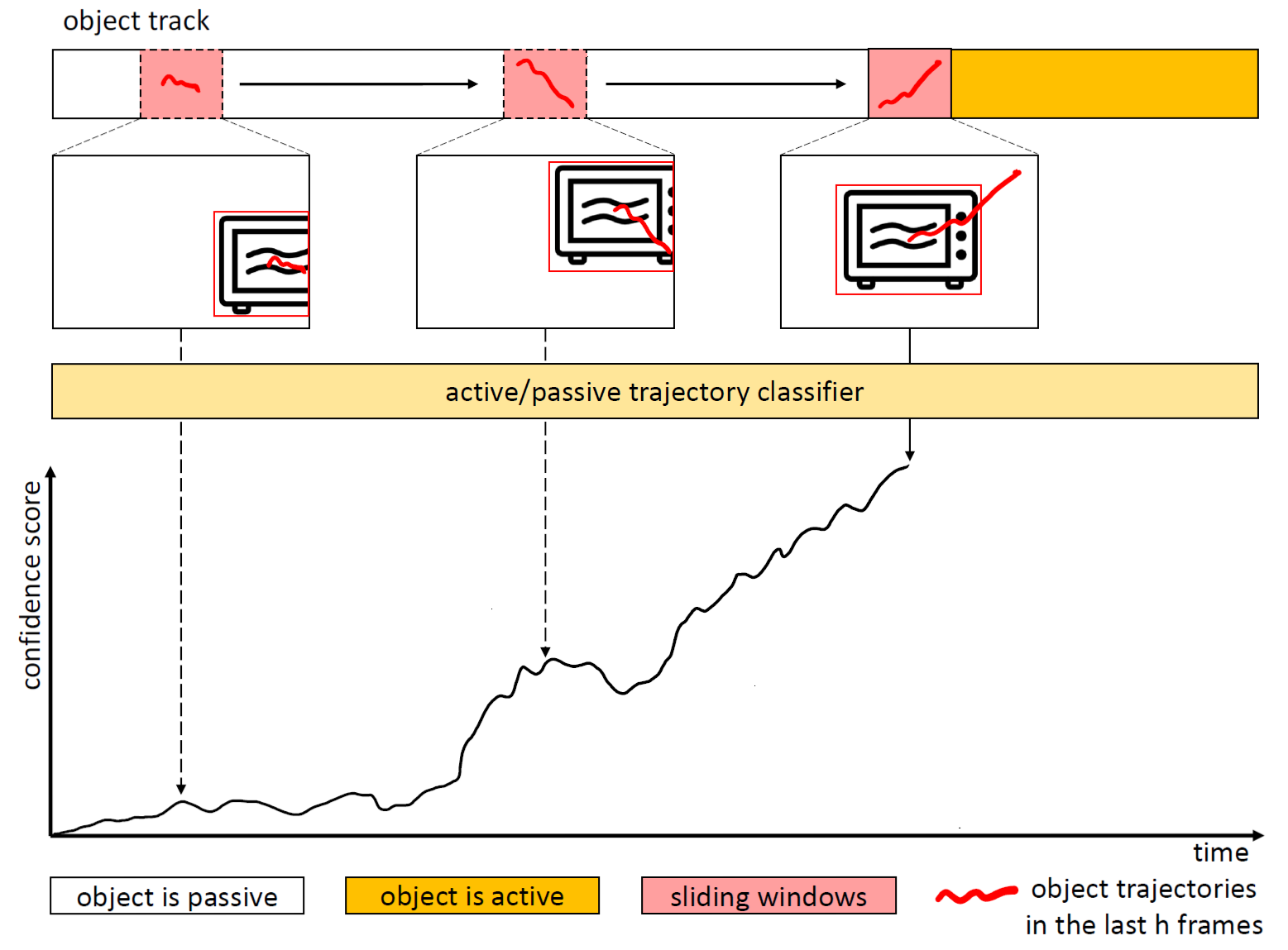
Sliding window processing of object tracks. At each time step, the trained binary classifier is run over the trajectories observed in the last h frames and a confidence score is computed.
VIDEO EXAMPLES (SUCCESS AND FAILURE EXAMPLES)
The videos below illustrate correct predictions and failure examples. Each video reports several sequences preceding the activation point of specific next-active-objects. In each frame of the video, we highlight ground truth next-active-objects (in red), discarded objects (in gray), positive and negative model predictions (in green and blue respectively). We also display the egocentric object trajectories observed in the last 30 frames of the video.
SUCCESS EXAMPLES
In the reported success samples, the method is able to correctly detect the next active object and discard other passive objects. It should be noted that next-active-objects do not appear always in the center of the frame and they are not always static. Moreover, the method is able to detect next-active-objects a few seconds in advance in many cases.
FAILURE EXAMPLES
In the reported failure samples, the method is not always able to correctly detect all next active objects and discard passive ones. It should be noted that, in many cases, detecting the next-active-object is not trivial even for the human observer.
Paper
[JVCI 2017] A. Furnari, S. Battiato, K. Grauman, G. M. Farinella, Next-Active-Object Prediction from Egocentric Videos, Journal of Visual Communication and Image Representation, 2017. Download Paper



