Exploiting Objective Text Description of Images
for Visual Sentiment Analysis
This paper addresses the problem of Visual Sentiment Analysis focusing on the estimation of the polarity of the sentiment evoked by an image. Starting from an embedding approach which exploits both visual and textual features, we attempt to boost the contribute of each input view. We propose to extract and employ an Objective Text description of images rather than the classic Subjective Text provided by the users (i.e., title, tags and image description). Objective Text is obtained from the visual content of the images through recent deep learning architectures which are used to classify object, scene and to perform image captioning. Objective Text features are then combined with visual features in an embedding space obtained with Canonical Correlation Analysis. The sentiment polarity is then inferred by a supervised Support Vector Machine. During the evaluation, we compared an extensive number of text and visual features combinations and baselines obtained by considering the state of the art methods. Experiments performed on a representative dataset of 47235 labelled samples demonstrate that the exploitation of Objective Text helps to outperform state-of-the-art for sentiment polarity estimation.
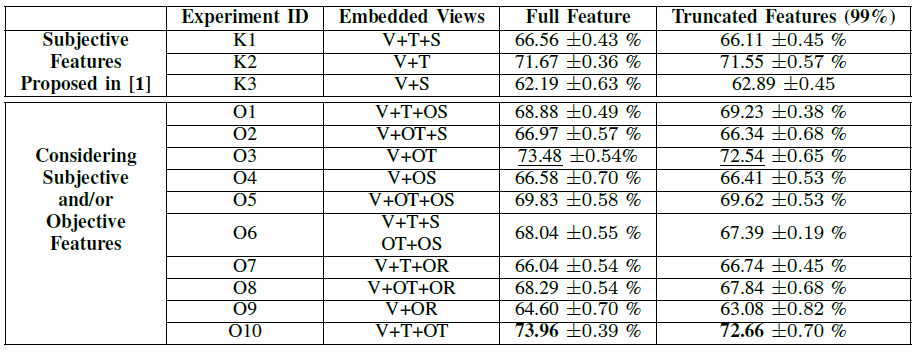
Experiments with Handcrafted Visual Features
Experiments with Deep Visual Features
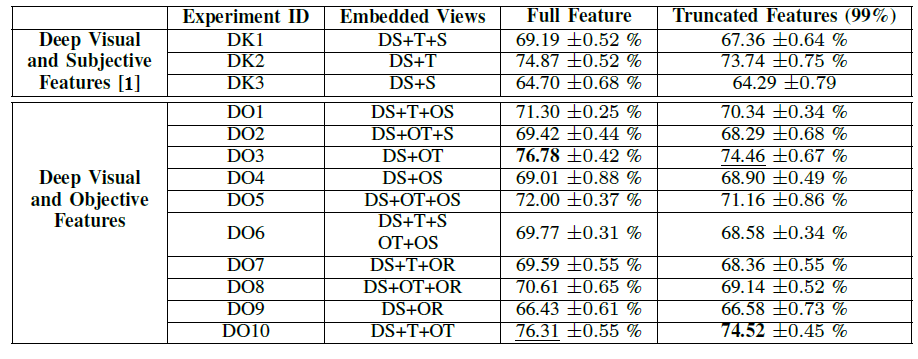
In the above tables all the tests with prefix "O" (Objective) are related to the exploitation of features extracted with the method we propose, whereas the features V, T and S refer to the features extracted with the method presented in [1] (Visual, Textual and Sentiment respectively). The third column lists the views used for the computation of the embedding space. For instance, V+T refers to the two-view embedding based on Visual and Textual features, V+OT+OS is related to the three-view embedding based on Visual, Objective Textual, and Objective Sentiment features, and so on.
Download the evaluation code
This archive contains the evaluation code used to obtain the values reported in the above tables.[1] Katsurai, Marie, and Shin'ichi Satoh. "Image sentiment analysis using latent correlations among visual, textual, and sentiment views." Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE, 2016.