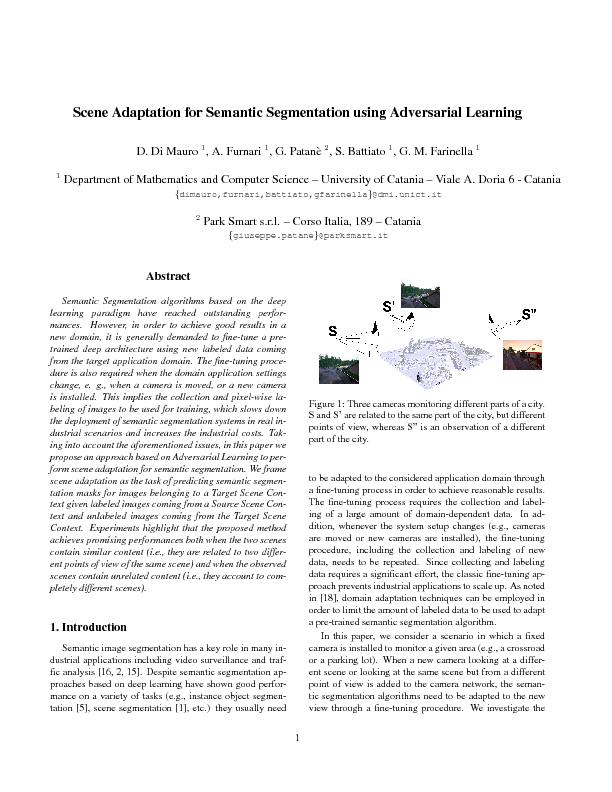ABSTRACT
Semantic Segmentation algorithms based on the deep learning paradigm have reached outstanding
performances. However, in order to achieve good results in a new domain, it is generally demanded
to fine-tune a pre-trained deep architecture using new labeled data coming from the target application
domain. The fine-tuning procedure is also required when the domain application settings
change, e. g., when a camera is moved, or a new camera is installed. This implies
the collection and pixel-wise labeling of images to be used for training, which
slows down the deployment of semantic segmentation systems in real industrial
scenarios and increases the industrial costs. Taking into account the aforementioned issues, in this
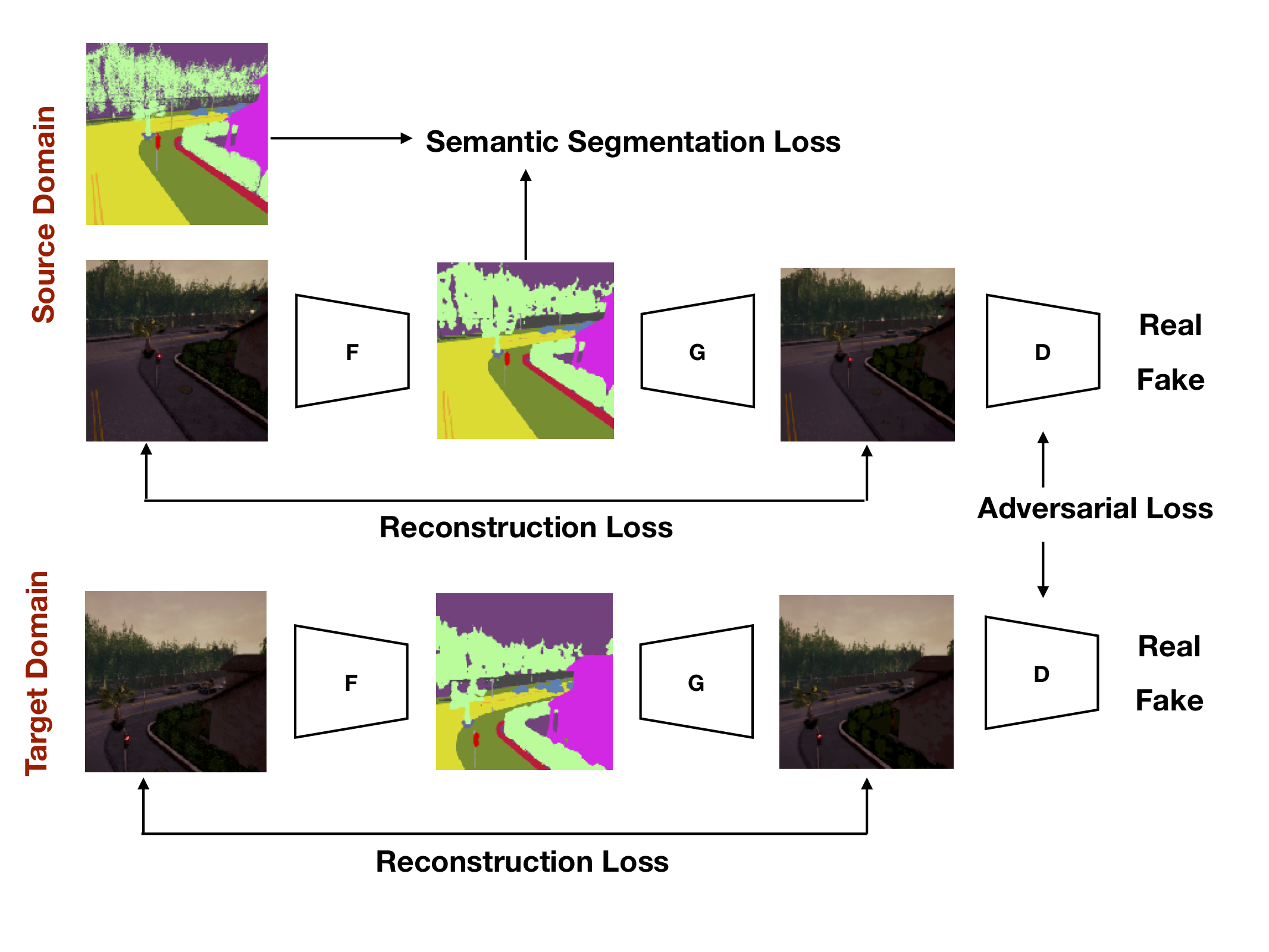
paper we propose an approach based on Adversarial Learning
to perform scene adaptation for semantic segmentation. We frame scene adaptation
as the task of predicting semantic segmentation masks for images belonging to
a Target Scene Context given labeled images coming from a Source Scene Context and unlabeled images coming
from the Target Scene Context. Experiments highlight that the proposed
method achieves promising performances both when the two scenes contain similar content (i.e., they are related
to two different points of view of the same scene) and when the observed scenes contain unrelated
content (i.e., they account to completely different scenes).